Initial release: ComfyUI-UniverSR
ComfyUI nodes for UniverSR (ICASSP 2026) — vocoder-free audio super-resolution (8/12/16/24 kHz → 48 kHz) via flow matching. - UniverSR Model Loader: presets auto-download to models/universr, plus local dir / raw .pth (from_local) loading, with caching. - UniverSR Super-Resolution: chunked overlap-add for long audio, per-channel stereo, seed control with global-RNG isolation, wet/dry blend, and an optional before/after spectrogram. - Vendors the universr inference package under vendor/ (prefers an installed copy); only extra dep beyond ComfyUI's stack is torchdiffeq. Co-Authored-By: Claude Opus 4.8 <noreply@anthropic.com>
This commit is contained in:
+10
@@ -0,0 +1,10 @@
|
||||
__pycache__/
|
||||
*.py[cod]
|
||||
*.egg-info/
|
||||
.pytest_cache/
|
||||
.DS_Store
|
||||
# anchored to repo root so the vendored universr/models/ package is NOT ignored
|
||||
/models/
|
||||
/ckpts/
|
||||
*.wav
|
||||
*.flac
|
||||
@@ -0,0 +1,21 @@
|
||||
MIT License
|
||||
|
||||
Copyright (c) 2026 Woongjib Choi, DSPAI Lab, Yonsei University
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
@@ -0,0 +1,108 @@
|
||||
# ComfyUI-UniverSR
|
||||
|
||||
ComfyUI nodes for **[UniverSR](https://github.com/woongzip1/UniverSR)** — *Unified and Versatile
|
||||
Audio Super-Resolution via Vocoder-Free Flow Matching* (ICASSP 2026,
|
||||
[arXiv:2510.00771](https://arxiv.org/abs/2510.00771)).
|
||||
|
||||
A single model upscales **8 / 12 / 16 / 24 kHz** effective bandwidth → **48 kHz** across speech,
|
||||
music and sound effects. It works directly in the complex‑STFT domain with flow matching — no neural
|
||||
vocoder — and regenerates the missing high‑frequency band rather than just interpolating.
|
||||
|
||||
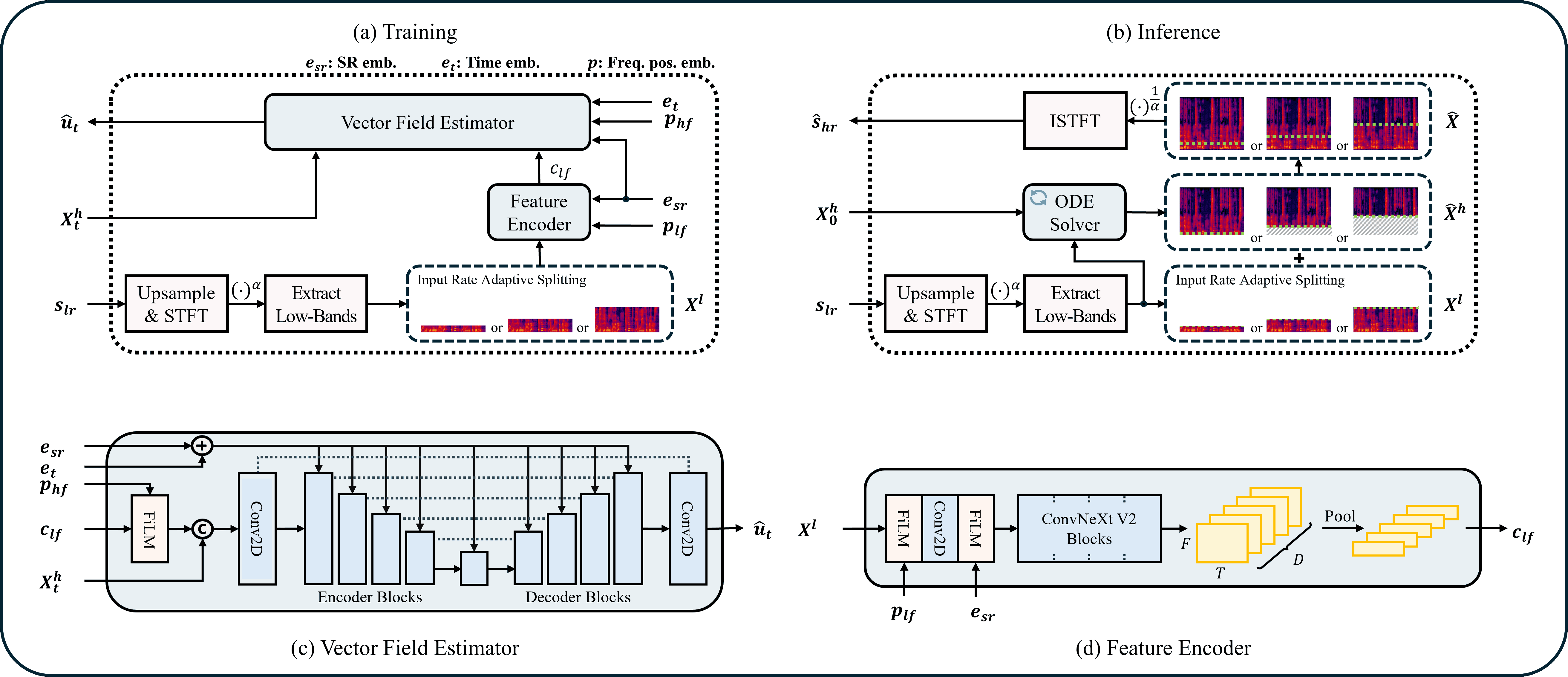
|
||||
|
||||
---
|
||||
|
||||
## Nodes
|
||||
|
||||
| Node | Output | Purpose |
|
||||
|---|---|---|
|
||||
| **UniverSR Model Loader** | `UNIVERSR_MODEL` | Loads + caches a checkpoint. Auto-downloads the presets to `models/universr/`. |
|
||||
| **UniverSR Super-Resolution** | `AUDIO`, `IMAGE` | Runs the SR. Chunks long audio (click-free overlap-add). Optional before/after spectrogram. |
|
||||
|
||||
Wire it up:
|
||||
|
||||
```
|
||||
LoadAudio ─────────────┐
|
||||
▼
|
||||
UniverSR Model Loader ─► UniverSR Super-Resolution ─► SaveAudio
|
||||
└─ spectrogram ─► PreviewImage
|
||||
```
|
||||
|
||||
### Model Loader
|
||||
- **model** — `universr-audio` (general; music/SFX/mixed, recommended) or `universr-speech` (voice).
|
||||
Each downloads ~230 MB to `models/universr/<name>` on first use. Local checkpoint folders placed
|
||||
in `models/universr/` also appear in this list.
|
||||
- **device** — `auto` / `cuda` / `cpu`.
|
||||
- **local_path** *(optional)* — override with a folder (`config.yaml` + `pytorch_model.bin`) or a raw
|
||||
`.pth`/`.ckpt` training checkpoint.
|
||||
- **config_path** *(optional)* — `config.yaml` for a raw checkpoint. Empty → the bundled default config.
|
||||
|
||||
### Super-Resolution
|
||||
- **input_sr** — the *effective bandwidth* of your content in Hz. The model treats everything up to
|
||||
`input_sr/2` as valid and **regenerates above it**.
|
||||
- `8000` → genuine low-rate audio (8 kHz → 48 kHz; the strongest, best-trained case).
|
||||
- `16000` → brighten muffled but full-rate audio by regenerating only above 8 kHz (most natural).
|
||||
- **ode_method** — `euler` (fastest) → `midpoint` (balanced) → `rk4` (best).
|
||||
- **ode_steps** — flow-matching steps. `4` is fast and validated; `4–10` is a good range.
|
||||
- **guidance_scale** — classifier-free guidance. Speech `1.0–1.5`, music `1.5–2.0`, SFX `~1.5`.
|
||||
Higher = denser highs but less faithful. `0` disables CFG.
|
||||
- **seed** — noise seed (`0` = random each run).
|
||||
- **chunk_seconds** / **overlap_seconds** — long-audio handling (see below). `chunk_seconds=0`
|
||||
processes the whole clip at once.
|
||||
- **blend** — wet/dry mix. `1.0` = full SR. Lower keeps more of the original (handy for *bandwidth
|
||||
extension* of already-48 kHz audio).
|
||||
- **unload_model** — free VRAM after the run.
|
||||
- **show_spectrogram** — also output a before/after spectrogram comparison `IMAGE`.
|
||||
|
||||
---
|
||||
|
||||
## Long audio & chunking
|
||||
|
||||
UniverSR runs the whole clip through a flow-matching ODE in one shot, which OOMs on long files
|
||||
(the upstream notebook added chunking specifically to survive clips > 2 min). This node chunks in the
|
||||
time domain and stitches the results with **overlap-add + linear crossfade** (weight-normalised), so
|
||||
seams are click-free — an improvement over the upstream GUI's naive concatenation. Drop
|
||||
`chunk_seconds` if you hit VRAM limits; raise `overlap_seconds` if you ever hear a seam. Stereo is
|
||||
processed per-channel and preserved.
|
||||
|
||||
> Compared to the `FoleyTune BWE` node (which brightens short foley clips and processes the whole clip
|
||||
> at once), this node adds the chunking needed for arbitrarily long sequences.
|
||||
|
||||
---
|
||||
|
||||
## Installation
|
||||
|
||||
```bash
|
||||
cd ComfyUI/custom_nodes
|
||||
git clone <this repo> ComfyUI-UniverSR
|
||||
pip install -r ComfyUI-UniverSR/requirements.txt
|
||||
```
|
||||
|
||||
The `universr` model code is **vendored** under `vendor/` (an installed `pip` copy is preferred if
|
||||
present), so the only dependency beyond ComfyUI's stack is **`torchdiffeq`** (plus `einops`, `timm`,
|
||||
`huggingface_hub`, `pyyaml`, which ComfyUI usually already has). Weights download automatically on
|
||||
first use.
|
||||
|
||||
---
|
||||
|
||||
## How it works (implementation note)
|
||||
|
||||
ComfyUI audio arrives at an arbitrary real sample rate. UniverSR's *file* path relies on
|
||||
`torchaudio.load` (fragile torchcodec backend), and its *tensor* path assumes the tensor is already at
|
||||
`input_sr`. So this node does the band-limit itself: resample to 48 kHz → downsample each chunk to
|
||||
`input_sr` (pure DSP, no codec) → hand UniverSR a genuine low-rate tensor to super-resolve. This
|
||||
exactly reproduces the model's training-time degradation.
|
||||
|
||||
## Credits & license
|
||||
|
||||
UniverSR © Woongjib Choi et al., DSPAI Lab, Yonsei University — released under the MIT License
|
||||
(see `LICENSE`). This node wrapper vendors the UniverSR inference code unmodified under `vendor/`.
|
||||
|
||||
```bibtex
|
||||
@inproceedings{choi2026universr,
|
||||
title = {{UniverSR}: Unified and Versatile Audio Super-Resolution via Vocoder-Free Flow Matching},
|
||||
author = {Choi, Woongjib and Lee, Sangmin and Lim, Hyungseob and Kang, Hong-Goo},
|
||||
booktitle = {IEEE ICASSP},
|
||||
year = {2026}
|
||||
}
|
||||
```
|
||||
+10
@@ -0,0 +1,10 @@
|
||||
"""ComfyUI-UniverSR — vocoder-free audio super-resolution (8/12/16/24 kHz -> 48 kHz)."""
|
||||
|
||||
try:
|
||||
from .nodes import NODE_CLASS_MAPPINGS, NODE_DISPLAY_NAME_MAPPINGS
|
||||
except Exception as e: # surface import errors in the ComfyUI log without crashing startup
|
||||
print(f"[ComfyUI-UniverSR] Failed to load nodes: {e}")
|
||||
NODE_CLASS_MAPPINGS = {}
|
||||
NODE_DISPLAY_NAME_MAPPINGS = {}
|
||||
|
||||
__all__ = ["NODE_CLASS_MAPPINGS", "NODE_DISPLAY_NAME_MAPPINGS"]
|
||||
@@ -0,0 +1,87 @@
|
||||
seed: 42
|
||||
|
||||
wandb:
|
||||
project_name: "UniverSR"
|
||||
entity: null # set to your wandb username or team
|
||||
run_name: "audio"
|
||||
notes: ""
|
||||
|
||||
dataloader:
|
||||
batch_size: 4
|
||||
num_workers: 4
|
||||
prefetch_factor: 2
|
||||
persistent_workers: True
|
||||
pin_memory: True
|
||||
|
||||
collator:
|
||||
sampling_rates_probs:
|
||||
8: 0.7
|
||||
12: 0.1
|
||||
16: 0.1
|
||||
24: 0.1
|
||||
validation_probs:
|
||||
8: 1.0
|
||||
|
||||
dataset:
|
||||
common:
|
||||
num_samples: 32767
|
||||
sr: 48000
|
||||
train:
|
||||
file_list: "./data/train.txt"
|
||||
val:
|
||||
file_list: "./data/val.txt"
|
||||
|
||||
path:
|
||||
class_path: universr.flow.path.OriginalCFMPath
|
||||
init_args:
|
||||
sigma_min: 1.0e-4
|
||||
|
||||
transform:
|
||||
window_fn: 'hann'
|
||||
n_fft: 1024
|
||||
sampling_rate: 48000
|
||||
hop_length: 512
|
||||
alpha: 0.2
|
||||
beta: 1
|
||||
comp_eps: 1.0e-4
|
||||
|
||||
model:
|
||||
in_channels: 2
|
||||
out_channels: 2
|
||||
dims: [96, 192, 384, 768]
|
||||
depths: [2, 2, 4, 2]
|
||||
drop_path: 0
|
||||
time_dim: 256
|
||||
cond_dim: 384
|
||||
total_freq_bins: 512
|
||||
hr_freq_bins: 432
|
||||
feature_enc_layers: 4
|
||||
cond_dropout_prob: 0.1
|
||||
sr_to_lr_bins: {8: 80, 12: 128, 16: 170, 24: 256}
|
||||
|
||||
scheduler:
|
||||
type: CosineLR
|
||||
init_args:
|
||||
num_warmup_steps: 10000
|
||||
num_training_steps: 5000000
|
||||
|
||||
optimizer:
|
||||
lr: 2.0e-4
|
||||
betas: [0.9, 0.99]
|
||||
|
||||
train:
|
||||
num_epochs: 200
|
||||
max_steps: 5000000
|
||||
ckpt_save_dir: ./ckpts/audio/
|
||||
ckpt_load_path: null
|
||||
log_step_interval: 1000
|
||||
val_step_interval: 50000
|
||||
num_val_log_samples: 5
|
||||
val_ode_steps: 4
|
||||
val_max_sec: 5
|
||||
|
||||
eval:
|
||||
ode_steps: 4
|
||||
guidance_scale: 1.5
|
||||
max_batches: null
|
||||
num_log_samples: 6
|
||||
@@ -0,0 +1,95 @@
|
||||
{
|
||||
"last_node_id": 5,
|
||||
"last_link_id": 4,
|
||||
"nodes": [
|
||||
{
|
||||
"id": 1,
|
||||
"type": "LoadAudio",
|
||||
"pos": [120, 200],
|
||||
"size": [320, 124],
|
||||
"flags": {},
|
||||
"order": 0,
|
||||
"mode": 0,
|
||||
"inputs": [],
|
||||
"outputs": [
|
||||
{"name": "AUDIO", "type": "AUDIO", "links": [1], "slot_index": 0}
|
||||
],
|
||||
"properties": {"Node name for S&R": "LoadAudio"},
|
||||
"widgets_values": ["example.wav", null, ""]
|
||||
},
|
||||
{
|
||||
"id": 2,
|
||||
"type": "UniverSRModelLoader",
|
||||
"pos": [120, 380],
|
||||
"size": [340, 130],
|
||||
"flags": {},
|
||||
"order": 1,
|
||||
"mode": 0,
|
||||
"inputs": [],
|
||||
"outputs": [
|
||||
{"name": "model", "type": "UNIVERSR_MODEL", "links": [2], "slot_index": 0}
|
||||
],
|
||||
"properties": {"Node name for S&R": "UniverSRModelLoader"},
|
||||
"widgets_values": ["universr-audio", "auto", "", ""]
|
||||
},
|
||||
{
|
||||
"id": 3,
|
||||
"type": "UniverSRSampler",
|
||||
"pos": [540, 200],
|
||||
"size": [340, 320],
|
||||
"flags": {},
|
||||
"order": 2,
|
||||
"mode": 0,
|
||||
"inputs": [
|
||||
{"name": "audio", "type": "AUDIO", "link": 1},
|
||||
{"name": "model", "type": "UNIVERSR_MODEL", "link": 2}
|
||||
],
|
||||
"outputs": [
|
||||
{"name": "audio", "type": "AUDIO", "links": [3], "slot_index": 0},
|
||||
{"name": "spectrogram", "type": "IMAGE", "links": [4], "slot_index": 1}
|
||||
],
|
||||
"properties": {"Node name for S&R": "UniverSRSampler"},
|
||||
"widgets_values": [8000, "midpoint", 4, 1.5, 0, "randomize", 10.0, 0.5, 1.0, false, true]
|
||||
},
|
||||
{
|
||||
"id": 4,
|
||||
"type": "PreviewAudio",
|
||||
"pos": [940, 200],
|
||||
"size": [320, 100],
|
||||
"flags": {},
|
||||
"order": 3,
|
||||
"mode": 0,
|
||||
"inputs": [
|
||||
{"name": "audio", "type": "AUDIO", "link": 3}
|
||||
],
|
||||
"outputs": [],
|
||||
"properties": {"Node name for S&R": "PreviewAudio"},
|
||||
"widgets_values": []
|
||||
},
|
||||
{
|
||||
"id": 5,
|
||||
"type": "PreviewImage",
|
||||
"pos": [940, 340],
|
||||
"size": [320, 280],
|
||||
"flags": {},
|
||||
"order": 4,
|
||||
"mode": 0,
|
||||
"inputs": [
|
||||
{"name": "images", "type": "IMAGE", "link": 4}
|
||||
],
|
||||
"outputs": [],
|
||||
"properties": {"Node name for S&R": "PreviewImage"},
|
||||
"widgets_values": []
|
||||
}
|
||||
],
|
||||
"links": [
|
||||
[1, 1, 0, 3, 0, "AUDIO"],
|
||||
[2, 2, 0, 3, 1, "UNIVERSR_MODEL"],
|
||||
[3, 3, 0, 4, 0, "AUDIO"],
|
||||
[4, 3, 1, 5, 0, "IMAGE"]
|
||||
],
|
||||
"groups": [],
|
||||
"config": {},
|
||||
"extra": {},
|
||||
"version": 0.4
|
||||
}
|
||||
@@ -0,0 +1,199 @@
|
||||
"""ComfyUI-UniverSR nodes.
|
||||
|
||||
Two-node design (mirrors the ComfyUI-Flash-AudioSR pattern):
|
||||
UniverSRModelLoader -> UNIVERSR_MODEL (loads + caches weights, auto-downloads)
|
||||
UniverSRSampler -> AUDIO, IMAGE (runs the super-resolution)
|
||||
"""
|
||||
|
||||
import torch
|
||||
|
||||
from . import universr_wrapper as usr
|
||||
|
||||
try:
|
||||
import comfy.model_management as mm
|
||||
HAS_COMFY = True
|
||||
except Exception: # pragma: no cover
|
||||
HAS_COMFY = False
|
||||
|
||||
|
||||
def _default_device() -> str:
|
||||
if HAS_COMFY:
|
||||
try:
|
||||
return "cuda" if mm.get_torch_device().type == "cuda" else "cpu"
|
||||
except Exception:
|
||||
pass
|
||||
return "cuda" if torch.cuda.is_available() else "cpu"
|
||||
|
||||
|
||||
# --------------------------------------------------------------------------- #
|
||||
# Model loader
|
||||
# --------------------------------------------------------------------------- #
|
||||
class UniverSRModelLoader:
|
||||
"""Load a UniverSR checkpoint. Auto-downloads the presets on first use.
|
||||
|
||||
Output: UNIVERSR_MODEL -> connect to UniverSR Super-Resolution.
|
||||
"""
|
||||
|
||||
DESCRIPTION = ("Load UniverSR (vocoder-free audio super-resolution, ICASSP 2026). "
|
||||
"Presets auto-download to models/universr on first use.")
|
||||
CATEGORY = "audio/UniverSR"
|
||||
|
||||
@classmethod
|
||||
def INPUT_TYPES(cls):
|
||||
choices = list(usr.HF_REPOS.keys()) + usr.list_local_models()
|
||||
return {
|
||||
"required": {
|
||||
"model": (choices, {
|
||||
"default": choices[0],
|
||||
"tooltip": "universr-audio = general (music/SFX/mixed, recommended); "
|
||||
"universr-speech = voice only. Both download (~230 MB) on first use. "
|
||||
"Local checkpoint folders in models/universr also appear here.",
|
||||
}),
|
||||
"device": (["auto", "cuda", "cpu"], {
|
||||
"default": "auto",
|
||||
"tooltip": "Device to load the model onto.",
|
||||
}),
|
||||
},
|
||||
"optional": {
|
||||
"local_path": ("STRING", {
|
||||
"default": "",
|
||||
"tooltip": "Override: a folder with config.yaml + pytorch_model.bin, "
|
||||
"or a raw .pth/.ckpt file (uses config_path or the bundled config).",
|
||||
}),
|
||||
"config_path": ("STRING", {
|
||||
"default": "",
|
||||
"tooltip": "config.yaml for a raw checkpoint given in local_path. "
|
||||
"Leave empty to use the bundled default config.",
|
||||
}),
|
||||
},
|
||||
}
|
||||
|
||||
RETURN_TYPES = ("UNIVERSR_MODEL",)
|
||||
RETURN_NAMES = ("model",)
|
||||
FUNCTION = "load"
|
||||
|
||||
def load(self, model, device, local_path="", config_path=""):
|
||||
dev = _default_device() if device == "auto" else device
|
||||
if dev == "cuda" and not torch.cuda.is_available():
|
||||
print("[UniverSR] CUDA unavailable, falling back to CPU")
|
||||
dev = "cpu"
|
||||
model_obj, cache_key = usr.load_model(model, dev, local_path=local_path, config_path=config_path)
|
||||
return ({"model": model_obj, "device": dev, "cache_key": cache_key},)
|
||||
|
||||
@classmethod
|
||||
def IS_CHANGED(cls, model, device, local_path="", config_path=""):
|
||||
return f"{model}:{device}:{local_path}:{config_path}"
|
||||
|
||||
|
||||
# --------------------------------------------------------------------------- #
|
||||
# Sampler
|
||||
# --------------------------------------------------------------------------- #
|
||||
class UniverSRSampler:
|
||||
"""Super-resolve audio to 48 kHz with UniverSR. Long clips are processed in
|
||||
overlapping chunks (click-free overlap-add) to stay within VRAM."""
|
||||
|
||||
DESCRIPTION = ("Upscale low-bandwidth audio to 48 kHz with UniverSR. Pick input_sr to "
|
||||
"match the effective bandwidth of your content (the model regenerates "
|
||||
"everything above input_sr/2).")
|
||||
CATEGORY = "audio/UniverSR"
|
||||
|
||||
@classmethod
|
||||
def INPUT_TYPES(cls):
|
||||
return {
|
||||
"required": {
|
||||
"audio": ("AUDIO", {}),
|
||||
"model": ("UNIVERSR_MODEL", {}),
|
||||
"input_sr": ([8000, 12000, 16000, 24000], {
|
||||
"default": 8000,
|
||||
"tooltip": "Effective input bandwidth (Hz). Content is treated as valid up to "
|
||||
"input_sr/2 and regenerated above it. 8000 = genuine low-rate audio "
|
||||
"(strongest, 8 kHz->48 kHz). 16000 = brighten muffled audio above 8 kHz.",
|
||||
}),
|
||||
},
|
||||
"optional": {
|
||||
"ode_method": (["midpoint", "euler", "rk4"], {
|
||||
"default": "midpoint",
|
||||
"tooltip": "ODE solver. euler (fastest) -> midpoint (balanced) -> rk4 (best).",
|
||||
}),
|
||||
"ode_steps": ("INT", {
|
||||
"default": 4, "min": 1, "max": 64, "step": 1,
|
||||
"tooltip": "Flow-matching integration steps. 4 is fast and validated; 4-10 is a good range.",
|
||||
}),
|
||||
"guidance_scale": ("FLOAT", {
|
||||
"default": 1.5, "min": 0.0, "max": 6.0, "step": 0.25,
|
||||
"tooltip": "Classifier-free guidance. Speech 1.0-1.5, music 1.5-2.0, SFX ~1.5. "
|
||||
"Higher = denser highs but less faithful. 0 disables CFG.",
|
||||
}),
|
||||
"seed": ("INT", {
|
||||
"default": 0, "min": 0, "max": 0xFFFFFFFFFFFFFFFF,
|
||||
"tooltip": "Noise seed for the flow-matching source. 0 = random each run.",
|
||||
}),
|
||||
"chunk_seconds": ("FLOAT", {
|
||||
"default": 10.0, "min": 0.0, "max": 120.0, "step": 0.5,
|
||||
"tooltip": "Process long audio in chunks of this length (seconds) to avoid OOM. "
|
||||
"0 = process the whole clip at once.",
|
||||
}),
|
||||
"overlap_seconds": ("FLOAT", {
|
||||
"default": 0.5, "min": 0.0, "max": 5.0, "step": 0.1,
|
||||
"tooltip": "Crossfade overlap between chunks (seconds). Prevents seam clicks.",
|
||||
}),
|
||||
"blend": ("FLOAT", {
|
||||
"default": 1.0, "min": 0.0, "max": 1.0, "step": 0.05,
|
||||
"tooltip": "Wet/dry mix. 1.0 = full super-resolution. Lower to keep more of the "
|
||||
"original (useful when brightening already-48 kHz audio).",
|
||||
}),
|
||||
"unload_model": ("BOOLEAN", {
|
||||
"default": False,
|
||||
"tooltip": "Free the model from VRAM after this run.",
|
||||
}),
|
||||
"show_spectrogram": ("BOOLEAN", {
|
||||
"default": True,
|
||||
"tooltip": "Also output a before/after spectrogram comparison image.",
|
||||
}),
|
||||
},
|
||||
}
|
||||
|
||||
RETURN_TYPES = ("AUDIO", "IMAGE")
|
||||
RETURN_NAMES = ("audio", "spectrogram")
|
||||
FUNCTION = "run"
|
||||
|
||||
def run(self, audio, model, input_sr, ode_method="midpoint", ode_steps=4,
|
||||
guidance_scale=1.5, seed=0, chunk_seconds=10.0, overlap_seconds=0.5,
|
||||
blend=1.0, unload_model=False, show_spectrogram=True):
|
||||
|
||||
model_obj = model["model"]
|
||||
waveform, sr = usr.comfy_audio_to_tensor(audio)
|
||||
dur = waveform.shape[-1] / max(sr, 1)
|
||||
print(f"[UniverSR] {tuple(waveform.shape)} @ {sr} Hz ({dur:.2f}s) -> 48 kHz | "
|
||||
f"input_sr={input_sr}, {ode_method}/{ode_steps}, cfg={guidance_scale}, blend={blend}")
|
||||
|
||||
out, dry48 = usr.super_resolve(
|
||||
model_obj, waveform, sr, int(input_sr),
|
||||
ode_method=ode_method, ode_steps=int(ode_steps), guidance_scale=guidance_scale,
|
||||
seed=int(seed), chunk_seconds=float(chunk_seconds),
|
||||
overlap_seconds=float(overlap_seconds), blend=float(blend),
|
||||
)
|
||||
|
||||
audio_out = usr.tensor_to_comfy_audio(out, usr.TARGET_SR)
|
||||
|
||||
spec = torch.zeros(1, 64, 64, 3)
|
||||
if show_spectrogram:
|
||||
in_mono = dry48[0].mean(0).numpy()
|
||||
out_mono = out[0].mean(0).numpy()
|
||||
spec = usr.make_spectrogram_image(in_mono, out_mono, int(input_sr))
|
||||
|
||||
if unload_model:
|
||||
usr.evict_model(model["cache_key"])
|
||||
|
||||
print(f"[UniverSR] Done -> {out.shape[-1] / usr.TARGET_SR:.2f}s at 48 kHz")
|
||||
return (audio_out, spec)
|
||||
|
||||
|
||||
NODE_CLASS_MAPPINGS = {
|
||||
"UniverSRModelLoader": UniverSRModelLoader,
|
||||
"UniverSRSampler": UniverSRSampler,
|
||||
}
|
||||
NODE_DISPLAY_NAME_MAPPINGS = {
|
||||
"UniverSRModelLoader": "UniverSR Model Loader",
|
||||
"UniverSRSampler": "UniverSR Super-Resolution",
|
||||
}
|
||||
@@ -0,0 +1,19 @@
|
||||
[project]
|
||||
name = "comfyui-universr"
|
||||
description = "ComfyUI nodes for UniverSR — vocoder-free audio super-resolution (8/12/16/24 kHz → 48 kHz) via flow matching."
|
||||
version = "1.0.0"
|
||||
license = {file = "LICENSE"}
|
||||
dependencies = [
|
||||
"torchdiffeq>=0.2.3",
|
||||
"einops>=0.7",
|
||||
"timm>=0.9",
|
||||
"huggingface_hub>=0.20",
|
||||
"pyyaml>=6.0",
|
||||
]
|
||||
|
||||
[project.urls]
|
||||
Repository = "https://github.com/woongzip1/UniverSR"
|
||||
Paper = "https://arxiv.org/abs/2510.00771"
|
||||
|
||||
[tool.comfy]
|
||||
DisplayName = "UniverSR"
|
||||
@@ -0,0 +1,8 @@
|
||||
# ComfyUI-UniverSR runtime deps.
|
||||
# torch / torchaudio / numpy / matplotlib are already shipped by ComfyUI.
|
||||
# The vendored `universr` package only needs these extras on top of ComfyUI's stack:
|
||||
torchdiffeq>=0.2.3
|
||||
einops>=0.7
|
||||
timm>=0.9
|
||||
huggingface_hub>=0.20
|
||||
pyyaml>=6.0
|
||||
@@ -0,0 +1,422 @@
|
||||
"""Core wrapper for ComfyUI-UniverSR.
|
||||
|
||||
Bootstraps the `universr` package (prefers a pip-installed copy, falls back to
|
||||
the vendored one under ./vendor), manages model loading/caching, and runs the
|
||||
super-resolution itself with optional overlap-add chunking for long audio.
|
||||
|
||||
UniverSR (ICASSP 2026) is a vocoder-free audio super-resolution model that
|
||||
regenerates high-frequency content in the complex-STFT domain via flow matching.
|
||||
A single model handles 8 / 12 / 16 / 24 kHz effective bandwidth -> 48 kHz.
|
||||
|
||||
Key design note — why we resample ourselves instead of handing UniverSR a file:
|
||||
UniverSR's `enhance()` file path calls `torchaudio.load`, whose torchcodec
|
||||
backend is fragile across environments; its *tensor* path assumes the tensor
|
||||
is already at `input_sr`. ComfyUI audio arrives at an arbitrary real sample
|
||||
rate, so we do the band-limit ourselves: resample to 48 kHz, downsample each
|
||||
chunk to `input_sr` (pure DSP, no codec), and hand UniverSR a genuine
|
||||
low-rate tensor to super-resolve. This reproduces the exact training-time
|
||||
degradation and was validated in the FoleyTune BWE node.
|
||||
"""
|
||||
|
||||
import os
|
||||
import threading
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
import torchaudio
|
||||
|
||||
# --------------------------------------------------------------------------- #
|
||||
# Optional ComfyUI integration (degrade gracefully outside ComfyUI / in tests)
|
||||
# --------------------------------------------------------------------------- #
|
||||
try:
|
||||
import comfy.model_management as mm
|
||||
import comfy.utils
|
||||
HAS_COMFY = True
|
||||
except Exception: # pragma: no cover - allows standalone import / pytest
|
||||
HAS_COMFY = False
|
||||
|
||||
try:
|
||||
import folder_paths
|
||||
HAS_FOLDER_PATHS = True
|
||||
except Exception: # pragma: no cover
|
||||
HAS_FOLDER_PATHS = False
|
||||
|
||||
|
||||
TARGET_SR = 48_000
|
||||
SUPPORTED_INPUT_SR = (8000, 12000, 16000, 24000)
|
||||
# UniverSR.enhance() zero-pads anything shorter than this (≈0.68 s @ 48 kHz) before
|
||||
# running the ODE, so chunks below it just waste compute — clamp to it.
|
||||
MODEL_MIN_SAMPLES = 32_768
|
||||
_NODE_DIR = os.path.dirname(os.path.abspath(__file__))
|
||||
_VENDOR_DIR = os.path.join(_NODE_DIR, "vendor")
|
||||
_BUNDLED_CONFIG = os.path.join(_NODE_DIR, "configs", "config.yaml")
|
||||
|
||||
# HuggingFace repos for the two released checkpoints.
|
||||
HF_REPOS = {
|
||||
"universr-audio": "woongzip1/universr-audio",
|
||||
"universr-speech": "woongzip1/universr-speech",
|
||||
}
|
||||
|
||||
|
||||
# --------------------------------------------------------------------------- #
|
||||
# Package bootstrap
|
||||
# --------------------------------------------------------------------------- #
|
||||
def get_universr_cls():
|
||||
"""Return the `UniverSR` class, preferring an installed copy over the vendored one."""
|
||||
try:
|
||||
from universr import UniverSR # installed (e.g. via the FoleyTune node)
|
||||
return UniverSR
|
||||
except Exception:
|
||||
pass
|
||||
import sys
|
||||
if _VENDOR_DIR not in sys.path:
|
||||
sys.path.insert(0, _VENDOR_DIR)
|
||||
try:
|
||||
from universr import UniverSR # vendored fallback
|
||||
return UniverSR
|
||||
except Exception as e: # pragma: no cover
|
||||
raise RuntimeError(
|
||||
"Could not import the 'universr' package (neither installed nor vendored). "
|
||||
"Try: pip install torchdiffeq (the only dependency ComfyUI does not already ship).\n"
|
||||
f"Underlying error: {e}"
|
||||
)
|
||||
|
||||
|
||||
# --------------------------------------------------------------------------- #
|
||||
# Model directory + cache
|
||||
# --------------------------------------------------------------------------- #
|
||||
def get_models_dir() -> str:
|
||||
if HAS_FOLDER_PATHS:
|
||||
base = folder_paths.models_dir
|
||||
else:
|
||||
base = os.path.join(_NODE_DIR, "..", "..", "models")
|
||||
return os.path.abspath(os.path.join(base, "universr"))
|
||||
|
||||
|
||||
def list_local_models() -> list:
|
||||
"""Subdirectories of models/universr that look like a UniverSR checkpoint dir."""
|
||||
root = get_models_dir()
|
||||
found = []
|
||||
if os.path.isdir(root):
|
||||
for name in sorted(os.listdir(root)):
|
||||
d = os.path.join(root, name)
|
||||
if os.path.isdir(d) and os.path.exists(os.path.join(d, "config.yaml")) \
|
||||
and os.path.exists(os.path.join(d, "pytorch_model.bin")):
|
||||
if name not in HF_REPOS:
|
||||
found.append(name)
|
||||
return found
|
||||
|
||||
|
||||
_MODEL_CACHE: dict = {}
|
||||
_CACHE_LOCK = threading.Lock()
|
||||
|
||||
|
||||
def _download_preset(name: str) -> str:
|
||||
"""Download a preset checkpoint into models/universr/<name> and return that dir."""
|
||||
from huggingface_hub import snapshot_download
|
||||
repo_id = HF_REPOS[name]
|
||||
target = os.path.join(get_models_dir(), name)
|
||||
have = os.path.exists(os.path.join(target, "config.yaml")) and \
|
||||
os.path.exists(os.path.join(target, "pytorch_model.bin"))
|
||||
if not have:
|
||||
os.makedirs(target, exist_ok=True)
|
||||
print(f"[UniverSR] Downloading {repo_id} -> {target} (~230 MB)...")
|
||||
snapshot_download(
|
||||
repo_id=repo_id,
|
||||
local_dir=target,
|
||||
allow_patterns=["config.yaml", "pytorch_model.bin"],
|
||||
)
|
||||
print(f"[UniverSR] Downloaded {name}.")
|
||||
return target
|
||||
|
||||
|
||||
def resolve_model_ref(model: str, local_path: str = "") -> tuple:
|
||||
"""Resolve the loader inputs to (kind, path). kind in {'dir', 'ckpt'}.
|
||||
|
||||
- local_path wins if set: a directory (config.yaml + pytorch_model.bin) -> 'dir';
|
||||
a .pth/.pt/.ckpt file -> 'ckpt' (loaded via from_local with a config).
|
||||
- a preset name ('universr-audio' / 'universr-speech') -> download -> 'dir'.
|
||||
- a local subdir name discovered under models/universr -> 'dir'.
|
||||
"""
|
||||
local_path = (local_path or "").strip()
|
||||
if local_path:
|
||||
if os.path.isdir(local_path):
|
||||
return ("dir", local_path)
|
||||
if os.path.isfile(local_path):
|
||||
return ("ckpt", local_path)
|
||||
raise FileNotFoundError(f"local_path does not exist: {local_path}")
|
||||
|
||||
if model in HF_REPOS:
|
||||
return ("dir", _download_preset(model))
|
||||
|
||||
cand = os.path.join(get_models_dir(), model)
|
||||
if os.path.isdir(cand):
|
||||
return ("dir", cand)
|
||||
raise FileNotFoundError(
|
||||
f"Unknown model '{model}'. Use a preset {list(HF_REPOS)}, a local subdir of "
|
||||
f"{get_models_dir()}, or set local_path."
|
||||
)
|
||||
|
||||
|
||||
def load_model(model: str, device: str, local_path: str = "", config_path: str = ""):
|
||||
"""Load (and cache) a UniverSR model. Returns (model_obj, cache_key)."""
|
||||
kind, path = resolve_model_ref(model, local_path)
|
||||
cache_key = f"{kind}:{os.path.abspath(path)}:{device}"
|
||||
|
||||
with _CACHE_LOCK:
|
||||
if cache_key in _MODEL_CACHE:
|
||||
print(f"[UniverSR] Using cached model ({cache_key})")
|
||||
return _MODEL_CACHE[cache_key], cache_key
|
||||
|
||||
UniverSR = get_universr_cls()
|
||||
if kind == "dir":
|
||||
print(f"[UniverSR] Loading from_pretrained({path}) on {device}")
|
||||
model_obj = UniverSR.from_pretrained(path, device=device)
|
||||
else:
|
||||
cfg = (config_path or "").strip() or _BUNDLED_CONFIG
|
||||
if not os.path.exists(cfg):
|
||||
raise FileNotFoundError(
|
||||
f"config_path required for a raw checkpoint and not found: {cfg}"
|
||||
)
|
||||
print(f"[UniverSR] Loading from_local(ckpt={path}, config={cfg}) on {device}")
|
||||
model_obj = UniverSR.from_local(ckpt_path=path, config_path=cfg, device=device)
|
||||
|
||||
model_obj.eval()
|
||||
n = sum(p.numel() for p in model_obj.parameters()) / 1e6
|
||||
print(f"[UniverSR] Ready - {n:.1f}M params on {device}")
|
||||
_MODEL_CACHE[cache_key] = model_obj
|
||||
return model_obj, cache_key
|
||||
|
||||
|
||||
def evict_model(cache_key: str):
|
||||
import gc
|
||||
with _CACHE_LOCK:
|
||||
_MODEL_CACHE.pop(cache_key, None)
|
||||
gc.collect()
|
||||
if torch.cuda.is_available():
|
||||
torch.cuda.empty_cache()
|
||||
print(f"[UniverSR] Model unloaded ({cache_key})")
|
||||
|
||||
|
||||
# --------------------------------------------------------------------------- #
|
||||
# Audio helpers
|
||||
# --------------------------------------------------------------------------- #
|
||||
def comfy_audio_to_tensor(audio) -> tuple:
|
||||
"""ComfyUI AUDIO (dict or legacy tuple) -> (waveform [B, C, T] float32 cpu, sr)."""
|
||||
if isinstance(audio, dict):
|
||||
waveform, sr = audio["waveform"], audio["sample_rate"]
|
||||
else:
|
||||
waveform, sr = audio
|
||||
if not isinstance(waveform, torch.Tensor):
|
||||
waveform = torch.as_tensor(waveform)
|
||||
waveform = waveform.detach().float().cpu()
|
||||
if waveform.dim() == 1: # (T,)
|
||||
waveform = waveform[None, None, :]
|
||||
elif waveform.dim() == 2: # (C, T)
|
||||
waveform = waveform[None, :, :]
|
||||
return waveform, int(sr)
|
||||
|
||||
|
||||
def tensor_to_comfy_audio(waveform: torch.Tensor, sr: int) -> dict:
|
||||
if waveform.dim() == 1:
|
||||
waveform = waveform[None, None, :]
|
||||
elif waveform.dim() == 2:
|
||||
waveform = waveform[None, :, :]
|
||||
return {"waveform": waveform.detach().cpu().contiguous(), "sample_rate": int(sr)}
|
||||
|
||||
|
||||
def _resample(x: torch.Tensor, orig: int, target: int) -> torch.Tensor:
|
||||
if orig == target:
|
||||
return x
|
||||
return torchaudio.functional.resample(x, orig, target)
|
||||
|
||||
|
||||
def _fit(x: torch.Tensor, n: int) -> torch.Tensor:
|
||||
"""Crop or zero-pad a 1-D tensor to exactly n samples."""
|
||||
if x.shape[-1] == n:
|
||||
return x
|
||||
if x.shape[-1] > n:
|
||||
return x[:n]
|
||||
return torch.nn.functional.pad(x, (0, n - x.shape[-1]))
|
||||
|
||||
|
||||
def _crossfade_window(length: int, ov: int, first: bool, last: bool) -> torch.Tensor:
|
||||
"""Linear fade-in/out over the overlap regions; flat 1.0 elsewhere.
|
||||
|
||||
Combined with weight-sum normalisation this gives click-free overlap-add.
|
||||
"""
|
||||
w = torch.ones(length)
|
||||
if ov > 0:
|
||||
f = min(ov, length)
|
||||
if not first:
|
||||
w[:f] = torch.minimum(w[:f], torch.linspace(0.0, 1.0, f))
|
||||
if not last:
|
||||
w[-f:] = torch.minimum(w[-f:], torch.linspace(1.0, 0.0, f))
|
||||
return w
|
||||
|
||||
|
||||
# --------------------------------------------------------------------------- #
|
||||
# Inference
|
||||
# --------------------------------------------------------------------------- #
|
||||
@torch.no_grad()
|
||||
def _enhance_segment(model, seg48: torch.Tensor, input_sr: int,
|
||||
ode_method: str, ode_steps: int, guidance_scale) -> torch.Tensor:
|
||||
"""Super-resolve one 48 kHz mono segment. Returns 1-D tensor @48 kHz on CPU."""
|
||||
low = _resample(seg48.unsqueeze(0), TARGET_SR, input_sr).squeeze(0) # genuine LR-rate signal
|
||||
cfg = float(guidance_scale) if (guidance_scale and guidance_scale > 0) else None
|
||||
out = model.enhance(
|
||||
low, input_sr=int(input_sr),
|
||||
ode_method=ode_method, ode_steps=int(ode_steps), guidance_scale=cfg,
|
||||
)
|
||||
return out.reshape(-1).float().cpu()
|
||||
|
||||
|
||||
def _chunk_starts(total: int, chunk: int, hop: int) -> list:
|
||||
if chunk <= 0 or total <= chunk:
|
||||
return [0]
|
||||
starts = list(range(0, max(1, total - chunk) + 1, hop))
|
||||
if starts[-1] + chunk < total:
|
||||
starts.append(total - chunk)
|
||||
return starts
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def _enhance_channel(model, ch48: torch.Tensor, input_sr, ode_method, ode_steps,
|
||||
guidance_scale, chunk: int, ov: int, pbar) -> torch.Tensor:
|
||||
T = ch48.shape[-1]
|
||||
if chunk <= 0 or T <= chunk:
|
||||
if pbar is not None:
|
||||
pbar.update(1)
|
||||
return _fit(_enhance_segment(model, ch48, input_sr, ode_method, ode_steps, guidance_scale), T)
|
||||
|
||||
hop = max(1, chunk - ov)
|
||||
starts = _chunk_starts(T, chunk, hop)
|
||||
out = torch.zeros(T)
|
||||
wsum = torch.zeros(T)
|
||||
for i, s in enumerate(starts):
|
||||
if HAS_COMFY:
|
||||
mm.throw_exception_if_processing_interrupted()
|
||||
e = min(s + chunk, T)
|
||||
enh = _fit(_enhance_segment(model, ch48[s:e], input_sr, ode_method, ode_steps, guidance_scale), e - s)
|
||||
w = _crossfade_window(e - s, ov, first=(i == 0), last=(e >= T))
|
||||
out[s:e] += enh * w
|
||||
wsum[s:e] += w
|
||||
if pbar is not None:
|
||||
pbar.update(1)
|
||||
return out / torch.clamp(wsum, min=1e-8)
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def super_resolve(model, waveform: torch.Tensor, sr: int, input_sr: int,
|
||||
ode_method: str = "midpoint", ode_steps: int = 4,
|
||||
guidance_scale=1.5, seed: int = 0,
|
||||
chunk_seconds: float = 10.0, overlap_seconds: float = 0.5,
|
||||
blend: float = 1.0):
|
||||
"""Run UniverSR over a [B, C, T] waveform. Returns (out [B, C, T48], dry48 [B, C, T48])."""
|
||||
if int(input_sr) not in SUPPORTED_INPUT_SR:
|
||||
raise ValueError(f"input_sr must be one of {SUPPORTED_INPUT_SR}, got {input_sr}")
|
||||
|
||||
waveform = waveform.float().cpu()
|
||||
if waveform.dim() != 3:
|
||||
raise ValueError(f"Expected a [B, C, T] waveform, got shape {tuple(waveform.shape)}")
|
||||
B, C, _ = waveform.shape
|
||||
dry48 = _resample(waveform, sr, TARGET_SR) # [B, C, T48]
|
||||
T48 = dry48.shape[-1]
|
||||
if T48 == 0: # empty input — nothing to do
|
||||
empty = torch.zeros(B, C, 0)
|
||||
return empty, empty
|
||||
|
||||
chunk = int(round(chunk_seconds * TARGET_SR)) if (chunk_seconds and chunk_seconds > 0) else 0
|
||||
if 0 < chunk < MODEL_MIN_SAMPLES:
|
||||
print(f"[UniverSR] chunk_seconds too small; raising to the model floor "
|
||||
f"({MODEL_MIN_SAMPLES / TARGET_SR:.2f}s).")
|
||||
chunk = MODEL_MIN_SAMPLES
|
||||
ov = max(0, min(int(round(overlap_seconds * TARGET_SR)), chunk - 1)) if chunk > 0 else 0
|
||||
n_per_ch = len(_chunk_starts(T48, chunk, max(1, chunk - ov))) if chunk > 0 else 1
|
||||
|
||||
pbar = comfy.utils.ProgressBar(B * C * n_per_ch) if HAS_COMFY else None
|
||||
|
||||
# Isolate the global RNG: snapshot, seed, run, restore. Without this the model's
|
||||
# torch.randn_like noise would advance (and a fixed seed would freeze) the global
|
||||
# generator that downstream ComfyUI nodes rely on. seed=0 → fresh OS entropy.
|
||||
cpu_rng = torch.get_rng_state()
|
||||
cuda_rng = torch.cuda.get_rng_state_all() if torch.cuda.is_available() else None
|
||||
actual_seed = int(seed) if (seed and int(seed) != 0) else int.from_bytes(os.urandom(8), "little")
|
||||
try:
|
||||
torch.manual_seed(actual_seed)
|
||||
if torch.cuda.is_available():
|
||||
torch.cuda.manual_seed_all(actual_seed)
|
||||
wet = torch.zeros(B, C, T48)
|
||||
for b in range(B):
|
||||
for c in range(C):
|
||||
wet[b, c] = _fit(
|
||||
_enhance_channel(model, dry48[b, c], input_sr, ode_method, ode_steps,
|
||||
guidance_scale, chunk, ov, pbar),
|
||||
T48,
|
||||
)
|
||||
finally:
|
||||
torch.set_rng_state(cpu_rng)
|
||||
if cuda_rng is not None:
|
||||
torch.cuda.set_rng_state_all(cuda_rng)
|
||||
|
||||
blend = float(blend)
|
||||
out = wet if blend >= 1.0 else (1.0 - blend) * dry48 + blend * wet
|
||||
return out.clamp(-1.0, 1.0), dry48
|
||||
|
||||
|
||||
# --------------------------------------------------------------------------- #
|
||||
# Spectrogram comparison (optional IMAGE output)
|
||||
# --------------------------------------------------------------------------- #
|
||||
def _stft_db(x: np.ndarray) -> np.ndarray:
|
||||
t = torch.from_numpy(np.ascontiguousarray(x)).float()
|
||||
win = torch.hann_window(1024)
|
||||
spec = torch.stft(t, n_fft=1024, hop_length=512, window=win, return_complex=True)
|
||||
db = 20.0 * torch.log10(spec.abs().clamp(min=1e-5))
|
||||
db = db - db.max()
|
||||
return db.numpy()
|
||||
|
||||
|
||||
def make_spectrogram_image(input48_mono: np.ndarray, output48_mono: np.ndarray,
|
||||
input_sr: int) -> torch.Tensor:
|
||||
"""Before/after spectrogram comparison -> IMAGE tensor [1, H, W, 3] in [0, 1].
|
||||
|
||||
Left panel is the band-limited input (content valid up to input_sr/2); right
|
||||
panel is the 48 kHz output. The dashed line marks the LR Nyquist, so the
|
||||
regenerated high-frequency band is the energy above it on the right.
|
||||
"""
|
||||
try:
|
||||
import matplotlib
|
||||
matplotlib.use("Agg")
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
# Visualise the band-limit the model actually saw, not the raw container.
|
||||
lr = torch.from_numpy(np.ascontiguousarray(input48_mono)).float()[None]
|
||||
lr = _resample(_resample(lr, TARGET_SR, int(input_sr)), int(input_sr), TARGET_SR).squeeze(0).numpy()
|
||||
n = min(len(lr), len(output48_mono), int(8.0 * TARGET_SR))
|
||||
lr, hr = lr[:n], output48_mono[:n]
|
||||
nyq = int(input_sr) / 2.0
|
||||
|
||||
fig, axes = plt.subplots(1, 2, figsize=(12, 4.0), facecolor="#0d0f16")
|
||||
for ax, sig, title, cmap in (
|
||||
(axes[0], lr, f"Input (<= {int(input_sr)//1000} kHz)", "magma"),
|
||||
(axes[1], hr, "UniverSR output (48 kHz)", "viridis"),
|
||||
):
|
||||
db = _stft_db(sig)
|
||||
ax.imshow(db, origin="lower", aspect="auto", cmap=cmap,
|
||||
extent=[0, n / TARGET_SR, 0, TARGET_SR / 2], vmin=-80, vmax=0)
|
||||
ax.axhline(nyq, color="w", ls="--", lw=0.8, alpha=0.6)
|
||||
ax.set_title(title, color="#cfe0ff", fontsize=10)
|
||||
ax.set_xlabel("Time (s)", color="#7a93bd", fontsize=8)
|
||||
ax.set_ylabel("Hz", color="#7a93bd", fontsize=8)
|
||||
ax.tick_params(colors="#5a6e90", labelsize=7)
|
||||
ax.set_facecolor("#0d0f16")
|
||||
fig.tight_layout()
|
||||
|
||||
fig.canvas.draw()
|
||||
# np.asarray(buffer_rgba()) yields (H, W, 4) at the real pixel size — robust to HiDPI.
|
||||
img = np.asarray(fig.canvas.buffer_rgba())[..., :3].astype(np.float32) / 255.0
|
||||
plt.close(fig)
|
||||
return torch.from_numpy(np.ascontiguousarray(img))[None]
|
||||
except Exception as e: # matplotlib missing / headless edge cases
|
||||
print(f"[UniverSR] Spectrogram render skipped: {e}")
|
||||
return torch.zeros(1, 64, 64, 3)
|
||||
Vendored
+4
@@ -0,0 +1,4 @@
|
||||
from universr.inference import UniverSR
|
||||
|
||||
__version__ = "0.1.0"
|
||||
__all__ = ["UniverSR"]
|
||||
Vendored
+9
@@ -0,0 +1,9 @@
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
|
||||
|
||||
def flow_matching_loss(predicted_vf: torch.Tensor, target_vf: torch.Tensor) -> torch.Tensor:
|
||||
"""
|
||||
Flow matching loss; L2 loss between estimated and target vector field.
|
||||
"""
|
||||
return F.mse_loss(predicted_vf, target_vf)
|
||||
Vendored
+54
@@ -0,0 +1,54 @@
|
||||
import importlib
|
||||
from abc import ABC, abstractmethod
|
||||
from typing import List, Optional, Tuple
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
class ConditionalProbabilityPath(nn.Module, ABC):
|
||||
"""Abstract base class for conditional probability paths in flow matching."""
|
||||
|
||||
@abstractmethod
|
||||
def sample_source(self, shape_ref: torch.Tensor) -> torch.Tensor:
|
||||
"""Sample from the source distribution. shape_ref is used only for shape/device."""
|
||||
|
||||
@abstractmethod
|
||||
def sample_xt(self, x0: torch.Tensor, x1: torch.Tensor, t: torch.Tensor) -> torch.Tensor:
|
||||
"""Interpolate between source x0 and target x1 at time t."""
|
||||
|
||||
@abstractmethod
|
||||
def get_target_vector_field(
|
||||
self, xt: torch.Tensor, x0: torch.Tensor, x1: torch.Tensor, t: torch.Tensor
|
||||
) -> torch.Tensor:
|
||||
"""Compute the target vector field u_t(xt | x1)."""
|
||||
|
||||
class OriginalCFMPath(ConditionalProbabilityPath):
|
||||
def __init__(self, sigma_min: float = 1e-4):
|
||||
super().__init__()
|
||||
self.sigma_min = sigma_min
|
||||
|
||||
def sample_source(self, shape_ref):
|
||||
return torch.randn_like(shape_ref)
|
||||
|
||||
def sample_xt(self, x0, x1, t):
|
||||
return t * x1 + (1 - t + self.sigma_min * t) * x0
|
||||
|
||||
def get_target_vector_field(self, xt, x0, x1, t):
|
||||
return x1 - (1 - self.sigma_min) * x0
|
||||
|
||||
def get_path(config):
|
||||
class_path = config.get("class_path")
|
||||
|
||||
if not class_path:
|
||||
raise ValueError("Configuration must contain a 'class_path' key")
|
||||
try:
|
||||
module_path, class_name = class_path.rsplit(".", 1)
|
||||
except ValueError:
|
||||
raise ValueError(f"Invalid class_path '{class_path}'. Must contain at least one")
|
||||
|
||||
module = importlib.import_module(module_path)
|
||||
Class = getattr(module, class_name)
|
||||
init_args = config.get("init_args", {})
|
||||
return Class(**init_args)
|
||||
|
||||
|
||||
Vendored
+127
@@ -0,0 +1,127 @@
|
||||
from abc import ABC, abstractmethod
|
||||
|
||||
import torch
|
||||
from torchdiffeq import odeint
|
||||
from tqdm import tqdm
|
||||
|
||||
from universr.models.unet import ConditionalVectorFieldModel
|
||||
|
||||
class ODE(ABC):
|
||||
@abstractmethod
|
||||
def drift_coefficient(self, xt: torch.Tensor, t: torch.Tensor, **kwargs) -> torch.Tensor:
|
||||
"""
|
||||
Returns the drift coefficient of the ODE.
|
||||
Args:
|
||||
- xt: state at time t, shape (bs, c, h, w)
|
||||
- t: time, shape (bs, 1)
|
||||
Returns:
|
||||
- drift_coefficient: shape (bs, c, h, w)
|
||||
"""
|
||||
pass
|
||||
|
||||
class Solver(ABC):
|
||||
# @abstractmethod
|
||||
def step(self, xt: torch.Tensor, t: torch.Tensor, dt: torch.Tensor, **kwargs):
|
||||
"""
|
||||
Takes one simulation step
|
||||
Args:
|
||||
- xt: state at time t, shape (bs, c, h, w)
|
||||
- t: time, shape (bs, 1, 1, 1)
|
||||
- dt: time, shape (bs, 1, 1, 1)
|
||||
Returns:
|
||||
- nxt: state at time t + dt (bs, c, h, w)
|
||||
"""
|
||||
pass
|
||||
|
||||
@torch.no_grad()
|
||||
def simulate(self, x: torch.Tensor, ts: torch.Tensor, **kwargs):
|
||||
"""
|
||||
Simulates using the discretization gives by ts
|
||||
Args:
|
||||
- x_init: initial state, shape (bs, c, h, w)
|
||||
- ts: timesteps, shape (bs, nts, 1, 1, 1)
|
||||
Returns:
|
||||
- x_final: final state at time ts[-1], shape (bs, c, h, w)
|
||||
"""
|
||||
nts = ts.shape[1]
|
||||
for t_idx in tqdm(range(nts - 1)):
|
||||
t = ts[:, t_idx]
|
||||
h = ts[:, t_idx + 1] - ts[:, t_idx]
|
||||
x = self.step(x, t, h, **kwargs)
|
||||
return x
|
||||
|
||||
@torch.no_grad()
|
||||
def simulate_with_trajectory(self, x: torch.Tensor, ts: torch.Tensor, **kwargs):
|
||||
"""
|
||||
Simulates using the discretization gives by ts
|
||||
Args:
|
||||
- x: initial state, shape (bs, c, h, w)
|
||||
- ts: timesteps, shape (bs, nts, 1, 1, 1)
|
||||
Returns:
|
||||
- xs: trajectory of xts over ts, shape (batch_size, nts, c, h, w)
|
||||
"""
|
||||
xs = [x.clone()]
|
||||
nts = ts.shape[1]
|
||||
for t_idx in tqdm(range(nts - 1)):
|
||||
t = ts[:,t_idx]
|
||||
h = ts[:, t_idx + 1] - ts[:, t_idx]
|
||||
x = self.step(x, t, h, **kwargs)
|
||||
xs.append(x.clone())
|
||||
return torch.stack(xs, dim=1)
|
||||
|
||||
class VectorFieldODE(ODE):
|
||||
def __init__(self, net:ConditionalVectorFieldModel) -> None:
|
||||
super().__init__()
|
||||
self.net = net
|
||||
|
||||
def drift_coefficient(self, xt: torch.Tensor, t: torch.Tensor, y: torch.Tensor, **kwargs) -> torch.Tensor:
|
||||
return self.net(xt, t, y, **kwargs)
|
||||
|
||||
class CFGVectorFieldODE(ODE):
|
||||
""" For Classifier Free Guidance """
|
||||
def __init__(self, net:ConditionalVectorFieldModel, guidance_scale: float = 1.0) -> None:
|
||||
super().__init__()
|
||||
self.net = net
|
||||
self.guidance_scale = guidance_scale
|
||||
|
||||
def drift_coefficient(self, xt: torch.Tensor, t: torch.Tensor, y: torch.Tensor, **kwargs) -> torch.Tensor:
|
||||
guided_vector_field = self.net(xt, t, y, **kwargs)
|
||||
unguided_vector_field = self.net(xt, t, None, **kwargs)
|
||||
|
||||
return (1-self.guidance_scale) * unguided_vector_field + self.guidance_scale * guided_vector_field
|
||||
|
||||
class EulerSolver(Solver):
|
||||
def __init__(self, ode: ODE):
|
||||
self.ode = ode
|
||||
|
||||
def step(self, xt: torch.Tensor, t: torch.Tensor, h: torch.Tensor, **kwargs):
|
||||
return xt + self.ode.drift_coefficient(xt,t, **kwargs) * h
|
||||
|
||||
class TorchDiffeqSolver(Solver):
|
||||
def __init__(self,
|
||||
ode: ODE,
|
||||
method: str = 'euler',
|
||||
atol: float = 1e-5,
|
||||
rtol: float = 1e-5,
|
||||
):
|
||||
super().__init__()
|
||||
self.ode = ode
|
||||
self.method = method
|
||||
self.atol = atol
|
||||
self.rtol = rtol
|
||||
|
||||
@torch.no_grad()
|
||||
def simulate(self, x_init: torch.Tensor, ts: torch.Tensor, **kwargs):
|
||||
"""
|
||||
x_init: [B,C,H,W]
|
||||
ts: [N]
|
||||
return: final state [B,C,H,W]
|
||||
"""
|
||||
func = lambda t, x: self.ode.drift_coefficient(xt=x, t=t, **kwargs)
|
||||
|
||||
xs = odeint(
|
||||
func=func,
|
||||
y0=x_init, t=ts,
|
||||
method=self.method,
|
||||
atol=self.atol, rtol=self.rtol) # [N,B,C,H,W]
|
||||
return xs[-1]
|
||||
Vendored
+351
@@ -0,0 +1,351 @@
|
||||
"""
|
||||
UniverSR: Unified and Versatile Audio Super-Resolution via Vocoder-Free Flow Matching
|
||||
Inference wrapper module.
|
||||
"""
|
||||
|
||||
import os
|
||||
from typing import Optional, Union
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
import torchaudio
|
||||
import yaml
|
||||
from huggingface_hub import hf_hub_download
|
||||
|
||||
from universr.models.unet import ConvNeXtUNetCond
|
||||
from universr.flow.path import OriginalCFMPath
|
||||
from universr.flow.solver import CFGVectorFieldODE, VectorFieldODE, TorchDiffeqSolver
|
||||
from universr.utils.spectral_ops import AmplitudeCompressedComplexSTFT
|
||||
|
||||
|
||||
# Supported input sample rates (kHz) and their corresponding LR frequency bins
|
||||
SUPPORTED_INPUT_SR = {8000, 12000, 16000, 24000}
|
||||
TARGET_SR = 48000
|
||||
|
||||
|
||||
class UniverSR(torch.nn.Module):
|
||||
"""
|
||||
UniverSR inference wrapper.
|
||||
|
||||
Performs audio super-resolution from low sample rates (8/12/16/24 kHz)
|
||||
to 48 kHz using vocoder-free flow matching in the complex STFT domain.
|
||||
|
||||
Example:
|
||||
>>> model = UniverSR.from_pretrained("woongzip1/universr-speech")
|
||||
>>> output = model.enhance("input.wav", input_sr=16000)
|
||||
>>> torchaudio.save("output.wav", output.cpu(), 48000)
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
model: ConvNeXtUNetCond,
|
||||
transform: AmplitudeCompressedComplexSTFT,
|
||||
path: OriginalCFMPath,
|
||||
device: str = "cuda",
|
||||
):
|
||||
super().__init__()
|
||||
self.model = model
|
||||
self.transform = transform
|
||||
self.path = path
|
||||
self._device = device
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(
|
||||
cls,
|
||||
repo_id_or_path: str,
|
||||
device: str = "cuda",
|
||||
revision: Optional[str] = None,
|
||||
) -> "UniverSR":
|
||||
"""
|
||||
Load a pretrained UniverSR model.
|
||||
|
||||
Args:
|
||||
repo_id_or_path: HuggingFace repo ID (e.g. "woongzip1/universr-speech")
|
||||
or local directory path containing config.yaml and pytorch_model.bin.
|
||||
device: Device to load the model on.
|
||||
revision: Optional HuggingFace revision (branch, tag, or commit hash).
|
||||
|
||||
Returns:
|
||||
UniverSR instance ready for inference.
|
||||
"""
|
||||
if os.path.isdir(repo_id_or_path):
|
||||
config_path = os.path.join(repo_id_or_path, "config.yaml")
|
||||
model_path = os.path.join(repo_id_or_path, "pytorch_model.bin")
|
||||
else:
|
||||
config_path = hf_hub_download(
|
||||
repo_id=repo_id_or_path, filename="config.yaml", revision=revision
|
||||
)
|
||||
model_path = hf_hub_download(
|
||||
repo_id=repo_id_or_path, filename="pytorch_model.bin", revision=revision
|
||||
)
|
||||
|
||||
# Load config
|
||||
with open(config_path, "r") as f:
|
||||
config = yaml.safe_load(f)
|
||||
|
||||
# Build model
|
||||
model = ConvNeXtUNetCond(**config["model"])
|
||||
state_dict = torch.load(model_path, map_location="cpu", weights_only=True)
|
||||
model.load_state_dict(state_dict)
|
||||
model.to(device).eval()
|
||||
|
||||
# Build transform
|
||||
transform = AmplitudeCompressedComplexSTFT(**config["transform"])
|
||||
transform.to(device)
|
||||
|
||||
# Build probability path
|
||||
path_args = config.get("path", {}).get("init_args", {"sigma_min": 1e-4})
|
||||
path = OriginalCFMPath(**path_args)
|
||||
|
||||
return cls(model=model, transform=transform, path=path, device=device)
|
||||
|
||||
@classmethod
|
||||
def from_local(
|
||||
cls,
|
||||
ckpt_path: str,
|
||||
config_path: str,
|
||||
device: str = "cuda",
|
||||
) -> "UniverSR":
|
||||
"""
|
||||
Load UniverSR from a local checkpoint (e.g. training checkpoint with optimizer state).
|
||||
|
||||
This handles the standard training checkpoint format where weights are stored
|
||||
under the 'model_state_dict' key, as opposed to from_pretrained() which expects
|
||||
a clean state_dict saved as pytorch_model.bin.
|
||||
|
||||
Args:
|
||||
ckpt_path: Path to checkpoint file (.pth).
|
||||
config_path: Path to YAML config file.
|
||||
device: Device to load the model on.
|
||||
|
||||
Returns:
|
||||
UniverSR instance ready for inference.
|
||||
"""
|
||||
with open(config_path, "r") as f:
|
||||
config = yaml.safe_load(f)
|
||||
|
||||
model = ConvNeXtUNetCond(**config["model"])
|
||||
ckpt = torch.load(ckpt_path, map_location="cpu", weights_only=False)
|
||||
|
||||
# Handle both formats: raw state_dict or training checkpoint
|
||||
if "model_state_dict" in ckpt:
|
||||
model.load_state_dict(ckpt["model_state_dict"])
|
||||
else:
|
||||
model.load_state_dict(ckpt)
|
||||
model.to(device).eval()
|
||||
|
||||
transform = AmplitudeCompressedComplexSTFT(**config["transform"])
|
||||
transform.to(device)
|
||||
|
||||
path_args = config.get("path", {}).get("init_args", {"sigma_min": 1e-4})
|
||||
path = OriginalCFMPath(**path_args)
|
||||
|
||||
return cls(model=model, transform=transform, path=path, device=device)
|
||||
|
||||
# ------------------------------------------------------------------ #
|
||||
# Public API #
|
||||
# ------------------------------------------------------------------ #
|
||||
|
||||
@torch.no_grad()
|
||||
def enhance(
|
||||
self,
|
||||
audio: Union[str, torch.Tensor, np.ndarray],
|
||||
input_sr: Optional[int] = None,
|
||||
target_sr: int = TARGET_SR,
|
||||
ode_method: str = "midpoint",
|
||||
ode_steps: int = 4,
|
||||
guidance_scale: Optional[float] = 1.5,
|
||||
) -> torch.Tensor:
|
||||
"""
|
||||
Enhance a low-resolution audio signal to high-resolution.
|
||||
|
||||
Args:
|
||||
audio: Input audio. Can be:
|
||||
- str: path to a .wav file
|
||||
- torch.Tensor: waveform tensor of shape (T,), (1, T), or (1, 1, T)
|
||||
- np.ndarray: waveform array
|
||||
input_sr: Effective bandwidth of the input in Hz (e.g. 8000, 16000).
|
||||
For file input: auto-detected from the file's native sample rate
|
||||
if it matches a supported rate (8/12/16/24 kHz). Required if the
|
||||
file is already at 48 kHz but has limited bandwidth.
|
||||
For tensor/array input: always required.
|
||||
target_sr: Target sample rate in Hz. Default: 48000.
|
||||
ode_method: ODE solver method. One of 'euler', 'midpoint', 'rk4'.
|
||||
ode_steps: Number of ODE integration steps.
|
||||
guidance_scale: Classifier-free guidance scale. None or 0 disables CFG.
|
||||
|
||||
Returns:
|
||||
Enhanced waveform tensor of shape (1,T) at target_sr.
|
||||
"""
|
||||
# Load audio
|
||||
wav, file_sr = self._load_audio(audio, input_sr=input_sr)
|
||||
wav = wav.to(self._device)
|
||||
|
||||
# Determine the effective bandwidth SR
|
||||
effective_sr = input_sr if input_sr is not None else file_sr
|
||||
|
||||
if effective_sr not in SUPPORTED_INPUT_SR:
|
||||
if effective_sr == target_sr and input_sr is None:
|
||||
raise ValueError(
|
||||
f"Input audio is already at {target_sr} Hz. "
|
||||
f"Please specify input_sr to indicate the effective bandwidth "
|
||||
f"(e.g., input_sr=16000). Supported: {sorted(SUPPORTED_INPUT_SR)}"
|
||||
)
|
||||
raise ValueError(
|
||||
f"Effective input sample rate {effective_sr} Hz is not supported. "
|
||||
f"Supported rates: {sorted(SUPPORTED_INPUT_SR)}"
|
||||
)
|
||||
|
||||
# Prepare the 48 kHz LR input for the model
|
||||
if file_sr == target_sr:
|
||||
# Simulate the training degradation: downsample → upsample to match
|
||||
wav = self._apply_bandwidth_limit(wav, effective_sr, target_sr)
|
||||
elif file_sr != target_sr:
|
||||
# File is truly low-resolution; resample up to 48 kHz
|
||||
wav = torchaudio.functional.resample(wav, orig_freq=file_sr, new_freq=target_sr)
|
||||
|
||||
# Minimum length guard
|
||||
MIN_SAMPLES = 32_768
|
||||
original_len = wav.shape[-1]
|
||||
wav = torch.nn.functional.pad(wav, (0, max(0, MIN_SAMPLES - wav.shape[-1])))
|
||||
|
||||
# Ensure shape is [B, C, T] = [1, 1, T]
|
||||
if wav.dim() == 1:
|
||||
wav = wav.unsqueeze(0).unsqueeze(0)
|
||||
elif wav.dim() == 2:
|
||||
wav = wav.unsqueeze(0)
|
||||
|
||||
sr_khz = effective_sr // 1000
|
||||
|
||||
# Run flow matching SR
|
||||
output = self._inference(wav, sr_khz, ode_method, ode_steps, guidance_scale)
|
||||
|
||||
# (1,T)
|
||||
return output[..., :original_len]
|
||||
|
||||
# ------------------------------------------------------------------ #
|
||||
# Internal methods #
|
||||
# ------------------------------------------------------------------ #
|
||||
|
||||
def _load_audio(
|
||||
self, audio: Union[str, torch.Tensor, np.ndarray], input_sr: Optional[int] = None,
|
||||
) -> tuple:
|
||||
"""
|
||||
Load and validate audio input.
|
||||
|
||||
Returns:
|
||||
(waveform, file_sr): The waveform tensor and its *actual* sample rate.
|
||||
"""
|
||||
if isinstance(audio, str):
|
||||
wav, file_sr = torchaudio.load(audio)
|
||||
# Mix to mono if stereo
|
||||
if wav.shape[0] > 1:
|
||||
wav = wav.mean(dim=0, keepdim=True)
|
||||
return wav, file_sr
|
||||
|
||||
if isinstance(audio, np.ndarray):
|
||||
audio = torch.from_numpy(audio).float()
|
||||
|
||||
if isinstance(audio, torch.Tensor):
|
||||
if input_sr is None:
|
||||
raise ValueError("input_sr is required when passing a tensor or array.")
|
||||
return audio.float(), input_sr
|
||||
|
||||
raise TypeError(f"Unsupported audio type: {type(audio)}")
|
||||
|
||||
def _apply_bandwidth_limit(
|
||||
self, wav: torch.Tensor, effective_sr: int, target_sr: int,
|
||||
) -> torch.Tensor:
|
||||
"""
|
||||
Simulate low-resolution input from a high-sample-rate waveform.
|
||||
|
||||
Applies the same downsample-then-upsample pipeline used during training
|
||||
(see WaveformCollator._apply_lpf) so that the spectral cutoff pattern
|
||||
matches what the model expects.
|
||||
|
||||
Args:
|
||||
wav: Waveform at target_sr. Shape: (1, T) or (T,).
|
||||
effective_sr: The effective bandwidth in Hz (e.g. 8000).
|
||||
target_sr: The native sample rate of wav (e.g. 48000).
|
||||
|
||||
Returns:
|
||||
Bandwidth-limited waveform at target_sr, same length as input.
|
||||
"""
|
||||
original_len = wav.shape[-1]
|
||||
lr = torchaudio.functional.resample(wav, orig_freq=target_sr, new_freq=effective_sr)
|
||||
lr = torchaudio.functional.resample(lr, orig_freq=effective_sr, new_freq=target_sr)
|
||||
return lr[..., :original_len]
|
||||
|
||||
def _preprocess(self, waveform: torch.Tensor) -> torch.Tensor:
|
||||
"""
|
||||
Convert waveform to amplitude-compressed complex STFT representation.
|
||||
[B, C, T] -> [B, 2, F-1, T_frames] (real/imag channels, drop Nyquist bin)
|
||||
"""
|
||||
spec = self.transform(waveform) # [B, C, F, T_frames] complex
|
||||
real = torch.view_as_real(spec.squeeze(1)) # [B, F, T_frames, 2]
|
||||
real = real.permute(0, 3, 1, 2) # [B, 2, F, T_frames]
|
||||
return real[:, :, :-1, :] # drop Nyquist bin
|
||||
|
||||
def _postprocess(self, spec: torch.Tensor) -> torch.Tensor:
|
||||
"""
|
||||
Convert STFT representation back to waveform.
|
||||
[B, 2, F-1, T_frames] -> [B, T]
|
||||
"""
|
||||
spec = torch.nn.functional.pad(spec, [0, 0, 0, 1], value=0) # restore Nyquist
|
||||
spec = spec.permute(0, 2, 3, 1).contiguous() # [B, F, T, 2]
|
||||
spec = torch.view_as_complex(spec) # [B, F, T] complex
|
||||
waveform = self.transform.invert(spec) # [B, T]
|
||||
return waveform
|
||||
|
||||
def _inference(
|
||||
self,
|
||||
lr_audio: torch.Tensor,
|
||||
sr_khz: int,
|
||||
ode_method: str,
|
||||
ode_steps: int,
|
||||
guidance_scale: Optional[float],
|
||||
) -> torch.Tensor:
|
||||
"""
|
||||
Core inference pipeline:
|
||||
1. STFT the (resampled) LR audio
|
||||
2. Extract LR condition bins
|
||||
3. Sample noise for HF region
|
||||
4. Solve ODE (flow matching)
|
||||
5. Concatenate LR + generated HF
|
||||
6. iSTFT to waveform
|
||||
"""
|
||||
# Frequency bin bookkeeping
|
||||
lr_bin_count = self.model.sr_to_lr_bins[sr_khz]
|
||||
hf_start_bin = self.model.total_freq_bins - self.model.hr_freq_bins
|
||||
|
||||
# STFT
|
||||
Y = self._preprocess(lr_audio) # [B, 2, F-1, T]
|
||||
Y_lr = Y[:, :, :lr_bin_count, :] # LR condition
|
||||
Y_hr = Y[:, :, hf_start_bin:, :] # HR target region (for shape reference)
|
||||
|
||||
# Initial noise
|
||||
x0 = self.path.sample_source(Y_hr).to(self._device)
|
||||
|
||||
# Build ODE solver
|
||||
if guidance_scale is not None and guidance_scale > 0:
|
||||
ode = CFGVectorFieldODE(net=self.model, guidance_scale=guidance_scale)
|
||||
else:
|
||||
ode = VectorFieldODE(net=self.model)
|
||||
solver = TorchDiffeqSolver(ode, method=ode_method)
|
||||
|
||||
# Time discretization
|
||||
ts = torch.linspace(0, 1, ode_steps + 1, device=self._device)
|
||||
|
||||
# Solve ODE
|
||||
x1_spec = solver.simulate(
|
||||
x0, ts=ts, y=Y_lr, sr_values=torch.tensor([sr_khz], device=self._device)
|
||||
)
|
||||
|
||||
# Concatenate LR bins + generated HF bins (handle overlapping region)
|
||||
slice_start = max(0, lr_bin_count - hf_start_bin)
|
||||
x1_spec = x1_spec[:, :, slice_start:, :]
|
||||
full_spec = torch.cat([Y_lr, x1_spec], dim=2)
|
||||
|
||||
# iSTFT
|
||||
output = self._postprocess(full_spec)
|
||||
return output
|
||||
Vendored
+470
@@ -0,0 +1,470 @@
|
||||
import math
|
||||
from abc import ABC, abstractmethod
|
||||
from typing import Optional
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
from einops import rearrange
|
||||
from timm.models.layers import DropPath, trunc_normal_
|
||||
|
||||
class ConditionalVectorFieldModel(nn.Module, ABC):
|
||||
"""
|
||||
Base class for DNN-based VF model
|
||||
MLP-parameterization of the learned vector field u_t^theta(x)
|
||||
"""
|
||||
|
||||
@abstractmethod
|
||||
def forward(self, x:torch.Tensor, t:torch.Tensor, y:torch.Tensor):
|
||||
"""
|
||||
Args:
|
||||
- x: (bs, c, h, w)
|
||||
- t: (bs, 1, 1, 1)
|
||||
- y: (bs,)
|
||||
Returns:
|
||||
- u_t^theta(x|y): (bs, c, h, w)
|
||||
"""
|
||||
pass
|
||||
|
||||
class SinusoidalTimeEmbedding(nn.Module):
|
||||
"""
|
||||
Based on https://github.com/lucidrains/denoising-diffusion-pytorch/blob/main/denoising_diffusion_pytorch/karras_unet.py#L183
|
||||
& DiffWave / WaveFM
|
||||
"""
|
||||
def __init__(self, dim: int=128, mode: str='learnable', time_scale=1):
|
||||
super().__init__()
|
||||
assert dim % 2 == 0, "Dimension must be an even number"
|
||||
assert mode in ['fixed', 'learnable'], "Mode must be 'fixed' or 'learnable'"
|
||||
|
||||
self.dim = dim # D
|
||||
self.half_dim = dim // 2
|
||||
self.mode = mode
|
||||
self.time_scale = time_scale # 1(diffusion) or 100(flow)
|
||||
|
||||
if self.mode == 'learnable':
|
||||
self.weights = nn.Parameter(torch.randn(1, self.half_dim)) # [1,D/2]
|
||||
|
||||
def forward(self, t: torch.Tensor) -> torch.Tensor:
|
||||
"""
|
||||
Args:
|
||||
- t: Time tensor. Shape can be [B] or [B, 1].
|
||||
Returns:
|
||||
- embeddings: Time embeddings of shape [B, D]
|
||||
"""
|
||||
# Ensure t has shape [B, 1] for broadcasting
|
||||
t = t.view(-1, 1)
|
||||
device = t.device
|
||||
|
||||
if self.mode == 'fixed':
|
||||
# Create a sequence from 0 to D/2 - 1
|
||||
pos = torch.arange(self.half_dim, device=device).unsqueeze(0) # [1,D/2]
|
||||
freqs = self.time_scale * t * 10.0 ** (pos * 4.0 / (self.half_dim - 1)) # 100 is a magnitude hyperparameter
|
||||
|
||||
sin_embed = torch.sin(freqs)
|
||||
cos_embed = torch.cos(freqs)
|
||||
|
||||
return torch.cat([sin_embed, cos_embed], dim=-1)
|
||||
|
||||
elif self.mode == 'learnable':
|
||||
freqs = t * self.weights * 2 * math.pi
|
||||
|
||||
sin_embed = torch.sin(freqs)
|
||||
cos_embed = torch.cos(freqs)
|
||||
|
||||
return torch.cat([sin_embed, cos_embed], dim=-1) * math.sqrt(2)
|
||||
|
||||
class GRN(nn.Module):
|
||||
""" GRN (Global Response Normalization) layer
|
||||
"""
|
||||
def __init__(self, dim):
|
||||
super().__init__()
|
||||
self.gamma = nn.Parameter(torch.zeros(1, 1, 1, dim))
|
||||
self.beta = nn.Parameter(torch.zeros(1, 1, 1, dim))
|
||||
|
||||
def forward(self, x):
|
||||
Gx = torch.norm(x, p=2, dim=(1,2), keepdim=True)
|
||||
Nx = Gx / (Gx.mean(dim=-1, keepdim=True) + 1e-6)
|
||||
return self.gamma * (x * Nx) + self.beta + x
|
||||
|
||||
class LayerNorm(nn.Module):
|
||||
""" LayerNorm that supports two data formats: channels_last (default) or channels_first.
|
||||
The ordering of the dimensions in the inputs. channels_last corresponds to inputs with
|
||||
shape (batch_size, height, width, channels) while channels_first corresponds to inputs
|
||||
with shape (batch_size, channels, height, width).
|
||||
"""
|
||||
def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):
|
||||
super().__init__()
|
||||
self.weight = nn.Parameter(torch.ones(normalized_shape))
|
||||
self.bias = nn.Parameter(torch.zeros(normalized_shape))
|
||||
self.eps = eps
|
||||
self.data_format = data_format
|
||||
if self.data_format not in ["channels_last", "channels_first"]:
|
||||
raise NotImplementedError
|
||||
self.normalized_shape = (normalized_shape, )
|
||||
|
||||
def forward(self, x):
|
||||
if self.data_format == "channels_last":
|
||||
return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
|
||||
elif self.data_format == "channels_first":
|
||||
u = x.mean(1, keepdim=True)
|
||||
s = (x - u).pow(2).mean(1, keepdim=True)
|
||||
x = (x - u) / torch.sqrt(s + self.eps)
|
||||
x = self.weight[:, None, None] * x + self.bias[:, None, None]
|
||||
return x
|
||||
|
||||
class Block(nn.Module):
|
||||
""" ConvNeXt V2 Block.
|
||||
|
||||
Args:
|
||||
dim (int): Number of input channels.
|
||||
drop_path (float): Stochastic depth rate. Default: 0.0
|
||||
"""
|
||||
def __init__(self, dim, drop_path=0.):
|
||||
super().__init__()
|
||||
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim, padding_mode="reflect")
|
||||
self.norm = LayerNorm(dim, eps=1e-6)
|
||||
self.pwconv1 = nn.Linear(dim, 4 * dim)
|
||||
self.act = nn.GELU()
|
||||
self.grn = GRN(4 * dim) # GRN for V2
|
||||
self.pwconv2 = nn.Linear(4 * dim, dim)
|
||||
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
|
||||
|
||||
def forward(self, x):
|
||||
# This Block preserves the input shape (C, H, W) -> (C, H, W)
|
||||
input = x
|
||||
x = self.dwconv(x)
|
||||
x = x.permute(0, 2, 3, 1) # [N,C,H,W] -> [N,H,W,C]
|
||||
x = self.norm(x)
|
||||
x = self.pwconv1(x)
|
||||
x = self.act(x)
|
||||
x = self.grn(x)
|
||||
x = self.pwconv2(x)
|
||||
x = x.permute(0, 3, 1, 2) # [N,H,W,C] -> [N,C,H,W]
|
||||
|
||||
x = input + self.drop_path(x) # Residual connection
|
||||
return x
|
||||
|
||||
class BlockWithEmbedding(nn.Module):
|
||||
""" ConvNeXt block with time embedding injection
|
||||
"""
|
||||
def __init__(self, dim, drop_path=0., time_embed_dim=128):
|
||||
super().__init__()
|
||||
self.block = Block(dim, drop_path)
|
||||
self.time_adapter = nn.Sequential(
|
||||
nn.Linear(time_embed_dim, time_embed_dim),
|
||||
nn.SiLU(),
|
||||
nn.Linear(time_embed_dim, dim),
|
||||
)
|
||||
def forward(self, x, t_embed):
|
||||
t_embed = self.time_adapter(t_embed).unsqueeze(-1).unsqueeze(-1) # [B,C,1,1]
|
||||
x = x + t_embed
|
||||
x = self.block(x)
|
||||
|
||||
return x
|
||||
|
||||
class EncoderBlock(nn.Module):
|
||||
def __init__(self, dim_in, dim_out, num_blocks, drop_path, time_embed_dim):
|
||||
super().__init__()
|
||||
self.blocks= nn.ModuleList(
|
||||
[BlockWithEmbedding(dim_in, drop_path, time_embed_dim)
|
||||
for _ in range(num_blocks)]
|
||||
)
|
||||
self.downsampler = nn.Sequential(
|
||||
LayerNorm(dim_in, eps=1e-6, data_format="channels_first"),
|
||||
nn.Conv2d(dim_in, dim_out, kernel_size=2, stride=2),
|
||||
)
|
||||
|
||||
def forward(self, x, t_emb):
|
||||
for block in self.blocks:
|
||||
x = block(x, t_emb)
|
||||
x = self.downsampler(x)
|
||||
return x
|
||||
|
||||
class Midcoder(nn.Module):
|
||||
def __init__(self, dim, num_blocks, drop_path, time_embed_dim):
|
||||
super().__init__()
|
||||
self.blocks = nn.ModuleList(
|
||||
[BlockWithEmbedding(dim, drop_path, time_embed_dim)
|
||||
for _ in range(num_blocks)]
|
||||
)
|
||||
|
||||
def forward(self, x, t_emb):
|
||||
for block in self.blocks:
|
||||
x = block(x, t_emb)
|
||||
return x
|
||||
|
||||
class DecoderBlock(nn.Module):
|
||||
def __init__(self, dim_in, dim_out, num_blocks, drop_path, time_embed_dim):
|
||||
super().__init__()
|
||||
self.upsampler = nn.ConvTranspose2d(dim_in, dim_out, kernel_size=2, stride=2)
|
||||
self.blocks = nn.ModuleList(
|
||||
[BlockWithEmbedding(dim_out, drop_path, time_embed_dim)
|
||||
for _ in range(num_blocks)]
|
||||
)
|
||||
def forward(self, x, t_emb):
|
||||
x = self.upsampler(x)
|
||||
for block in self.blocks:
|
||||
x = block(x, t_emb)
|
||||
return x
|
||||
|
||||
class ConditioningEncoder2D(nn.Module):
|
||||
def __init__(self, cond_dim, num_blocks=3):
|
||||
"""
|
||||
Args:
|
||||
cond_dim (int): The main conditioning dimension (D).
|
||||
num_blocks (int): The number of shared 2D ConvNeXt blocks.
|
||||
"""
|
||||
super().__init__()
|
||||
self.cond_dim = cond_dim
|
||||
self.film_generator = nn.Linear(cond_dim, 4)
|
||||
self.head = nn.Conv2d(2, cond_dim, kernel_size=1)
|
||||
self.sr_adapter = nn.Sequential(
|
||||
nn.Linear(cond_dim, cond_dim),
|
||||
nn.GELU(),
|
||||
nn.Linear(cond_dim, cond_dim * 2)
|
||||
)
|
||||
self.blocks = nn.Sequential(*[
|
||||
Block(dim=cond_dim) for _ in range(num_blocks)
|
||||
])
|
||||
self.freq_pool = nn.AdaptiveAvgPool2d((1,None))
|
||||
|
||||
def forward(self, y_lr, f_emb_lr, sr_emb):
|
||||
"""
|
||||
Args:
|
||||
y_lr (Tensor): LR Spec [B, 2, F1, T]
|
||||
f_emb : Freq positional embedding for lr spec [F1,D]
|
||||
sr_emb: Sampling rate embedding [B,D]
|
||||
Returns:
|
||||
z (Tensor): Conditioning Emb [B, D, T]
|
||||
"""
|
||||
film_params = self.film_generator(f_emb_lr) # [F1, 4]
|
||||
gamma, beta = torch.chunk(film_params, chunks=2, dim=-1) # [F1,2]
|
||||
gamma = rearrange(gamma, 'f c -> 1 c f 1') # [1,2,F1,1]
|
||||
beta = rearrange(beta, 'f c -> 1 c f 1') # [1,2,F1,1]
|
||||
z = y_lr * gamma + beta # [B, 2, F1, T]
|
||||
z = self.head(z) # [B,D,F1,T]
|
||||
|
||||
sr_film_params = self.sr_adapter(sr_emb) # [B, 2*D]
|
||||
sr_gamma, sr_beta = torch.chunk(sr_film_params, 2, dim=-1) # [B,D]
|
||||
sr_gamma = sr_gamma.unsqueeze(-1).unsqueeze(-1) # [B,D,1,1]
|
||||
sr_beta = sr_beta.unsqueeze(-1).unsqueeze(-1) # [B,D,1,1]
|
||||
z = z * sr_gamma + sr_beta # [B,D,F1,T]
|
||||
z = self.blocks(z) # [B,D,F1,T]
|
||||
z = self.freq_pool(z).squeeze(2) # [B,D,T]
|
||||
return z
|
||||
|
||||
class FrequencyPositionalEmbedding(nn.Module):
|
||||
def __init__(self, num_bins: int, emb_dim: int):
|
||||
super().__init__()
|
||||
# (F, D)
|
||||
pe = torch.zeros(num_bins, emb_dim)
|
||||
position = torch.arange(num_bins, dtype=torch.float32).unsqueeze(1) # (F,1)
|
||||
div_term = torch.exp(
|
||||
torch.arange(0, emb_dim, 2, dtype=torch.float32) *
|
||||
-(math.log(10000.0) / emb_dim)
|
||||
) # (D/2,)
|
||||
pe[:, 0::2] = torch.sin(position * div_term)
|
||||
pe[:, 1::2] = torch.cos(position * div_term)
|
||||
self.register_buffer('pe', pe)
|
||||
|
||||
def forward(self):
|
||||
# returns (F, D)
|
||||
return self.pe
|
||||
|
||||
class ConvNeXtUNetCond(ConditionalVectorFieldModel):
|
||||
def __init__(self, in_channels=2, out_channels=2,
|
||||
dims=[64,128,256,512], depths=[2,2,2,4],
|
||||
drop_path=0., time_dim=128,
|
||||
cond_dim=256, # D1
|
||||
total_freq_bins=512,
|
||||
hr_freq_bins=432,
|
||||
feature_enc_layers=10,
|
||||
cond_dropout_prob=0.1,
|
||||
sr_to_lr_bins={8: 80, 12: 128, 16: 170, 24: 256},
|
||||
):
|
||||
super().__init__()
|
||||
self.strides = 2**len(dims)
|
||||
self.time_embedder = SinusoidalTimeEmbedding(dim=time_dim)
|
||||
self.total_freq_bins = total_freq_bins
|
||||
self.hr_freq_bins = hr_freq_bins
|
||||
self.sr_to_lr_bins = sr_to_lr_bins
|
||||
self.sr_values_list = sorted(list(sr_to_lr_bins.keys())) # (8,12,16,24) kHz
|
||||
self.sr_to_idx = {sr: i for i, sr in enumerate(self.sr_values_list)}
|
||||
self.sr_embedder = nn.Embedding(len(self.sr_values_list), cond_dim) # [4,D]
|
||||
self.cond_dropout_prob = cond_dropout_prob
|
||||
self.cond_dim = cond_dim
|
||||
self.uncond_emb = nn.Parameter(torch.randn(cond_dim))
|
||||
self.sr_projector = nn.Linear(cond_dim, time_dim) # projector to t_emb
|
||||
|
||||
self.freq_pos_enc = FrequencyPositionalEmbedding(num_bins=total_freq_bins, emb_dim=cond_dim)
|
||||
self.film_generator = nn.Linear(cond_dim, cond_dim * 2)
|
||||
|
||||
self.conditioning_encoder = ConditioningEncoder2D(
|
||||
cond_dim=cond_dim,
|
||||
num_blocks=feature_enc_layers,
|
||||
)
|
||||
|
||||
self.init_conv = nn.Sequential(
|
||||
nn.Conv2d(in_channels+cond_dim, dims[0], kernel_size=1),
|
||||
LayerNorm(dims[0], eps=1e-6, data_format="channels_first")
|
||||
)
|
||||
self.encoders = nn.ModuleList()
|
||||
self.decoders = nn.ModuleList()
|
||||
|
||||
# Encoder
|
||||
for i in range(len(depths)):
|
||||
dim_in = dims[i]
|
||||
dim_out = dims[i+1] if i+1 < len(dims) else dims[i]
|
||||
self.encoders.append(EncoderBlock(dim_in, dim_out, depths[i], drop_path, time_dim))
|
||||
|
||||
# Midcoder
|
||||
self.midcoder = Midcoder(dims[-1], depths[-1], drop_path, time_dim)
|
||||
|
||||
# Decoder
|
||||
for i in reversed(range(len(depths))):
|
||||
dim_in = dims[i+1] if i+1 < len(dims) else dims[i]
|
||||
dim_out = dims[i]
|
||||
self.decoders.append(DecoderBlock(dim_in, dim_out, depths[i], drop_path, time_dim))
|
||||
|
||||
self.final_conv = nn.Conv2d(dims[0], out_channels, kernel_size=1)
|
||||
self.apply(self._init_weights)
|
||||
|
||||
def _init_weights(self, m):
|
||||
if isinstance(m, (nn.Conv2d, nn.Linear)):
|
||||
trunc_normal_(m.weight, std=.02)
|
||||
nn.init.constant_(m.bias, 0)
|
||||
|
||||
def _pad_frames(self, x):
|
||||
num_frames = x.shape[-1]
|
||||
pad_len = (self.strides - num_frames % self.strides) % self.strides
|
||||
if pad_len:
|
||||
x = torch.nn.functional.pad(x, [0,pad_len,0,0], mode='reflect')
|
||||
assert x.shape[-1] % self.strides == 0, \
|
||||
f"After padding, time dim:{x.shape(-1)} must be multiples of {self.strides}"
|
||||
return x, pad_len
|
||||
|
||||
def forward(self, x, t, y, sr_values):
|
||||
"""
|
||||
x : x_t noisy spec [B,2,F,T]
|
||||
t : time embedding [B,1] or [B]
|
||||
y : condition lr spectrum [B,2,F,T]
|
||||
sr_values: input sampling_rate [B] or [1]
|
||||
"""
|
||||
# Pad logic
|
||||
x, pad_len = self._pad_frames(x)
|
||||
if pad_len > 0 and y is not None:
|
||||
y = torch.nn.functional.pad(y, [0, pad_len, 0, 0], mode='reflect')
|
||||
B, _, F, T = x.shape
|
||||
|
||||
# get number of lr bins for input sr
|
||||
if isinstance(sr_values, int):
|
||||
current_sr = sr_values
|
||||
else:
|
||||
current_sr = sr_values[0].item() if hasattr(sr_values[0], 'item') else sr_values[0]
|
||||
|
||||
lr_bin_count = self.sr_to_lr_bins[current_sr]
|
||||
|
||||
# freq pe
|
||||
pe_full = self.freq_pos_enc() # [F,D]
|
||||
pe_low = pe_full[:lr_bin_count,:] # [F1,D]
|
||||
hf_start_bin = self.total_freq_bins - self.hr_freq_bins # 512 - 432
|
||||
pe_high = pe_full[hf_start_bin:, :] # [F2=432,D]
|
||||
|
||||
# time / sr embedding
|
||||
t_embed = self.time_embedder(t) # [B,timedim]
|
||||
sr_idx = self.sr_to_idx[current_sr]
|
||||
sr_emb = self.sr_embedder(torch.tensor([sr_idx], device=x.device)).expand(B,-1) # [B, D]
|
||||
t_embed = t_embed + self.sr_projector(sr_emb) # [B, timedim]
|
||||
|
||||
if y is not None: # (Training)
|
||||
y_cond_real = self.conditioning_encoder(y, pe_low, sr_emb) # [B,D,T]
|
||||
# Uncond token masking
|
||||
if self.training and self.cond_dropout_prob > 0:
|
||||
# random mask for uncond
|
||||
mask = (torch.rand(B, device=x.device) < self.cond_dropout_prob) # [B]
|
||||
uncond = self.uncond_emb.reshape(1,self.cond_dim,1).expand(B,self.cond_dim,T) # [B,D,T]
|
||||
y_cond = torch.where(mask.reshape(B,1,1), uncond, y_cond_real)
|
||||
else:
|
||||
y_cond = y_cond_real
|
||||
else: # Unconditional (inference)
|
||||
y_cond = self.uncond_emb.reshape(1,self.cond_dim,1).expand(B,self.cond_dim,T)
|
||||
|
||||
y_cond = y_cond.unsqueeze(2) # [B,D,1,T]
|
||||
|
||||
# FiLM Conditioning of freq-bins
|
||||
film_params = self.film_generator(pe_high) # [F2,D] -> [F2,2D]
|
||||
gamma_high, beta_high = torch.chunk(film_params, chunks=2, dim=-1) # [F2, D]
|
||||
gamma_high = rearrange(gamma_high, 'f d -> 1 d f 1') # [1,D,F2,1]
|
||||
beta_high = rearrange(beta_high, 'f d -> 1 d f 1') # [1,D,F2,1]
|
||||
spatial_cond = y_cond * gamma_high + beta_high # [B,D,F2,T]
|
||||
|
||||
x = torch.cat([x, spatial_cond], dim=1) # [B,2+D,F2,T]
|
||||
|
||||
x = self.init_conv(x)
|
||||
skip_connections = [x]
|
||||
|
||||
for encoder in self.encoders:
|
||||
x = encoder(x, t_embed)
|
||||
skip_connections.append(x)
|
||||
|
||||
x = self.midcoder(x, t_embed)
|
||||
|
||||
for decoder in self.decoders:
|
||||
skip = skip_connections.pop()
|
||||
if x.shape != skip.shape:
|
||||
x = nn.functional.interpolate(x, size=skip.shape[2:])
|
||||
x = x + skip
|
||||
x = decoder(x, t_embed)
|
||||
|
||||
skip = skip_connections.pop()
|
||||
x = x + skip
|
||||
x = self.final_conv(x)
|
||||
|
||||
# Crop out
|
||||
if pad_len:
|
||||
x = x[...,:-pad_len]
|
||||
return x
|
||||
|
||||
def main():
|
||||
"""
|
||||
Dummy forward pass test for ConvNeXtUNetCond.
|
||||
"""
|
||||
from torchinfo import summary
|
||||
|
||||
batch_size = 2
|
||||
hr_freq_bins = 432 # High-res bins to be generated (fixed)
|
||||
lr_freq_bins = 128 # Low-res bins for this specific test case (e.g., for 8kHz)
|
||||
T = 256 # Number of time frames
|
||||
|
||||
sr_config = {8: 80, 12: 128, 16: 170, 24: 256}
|
||||
|
||||
model = ConvNeXtUNetCond(
|
||||
in_channels=2,
|
||||
out_channels=2,
|
||||
dims=[96, 192, 384, 768],
|
||||
depths=[2, 2, 4, 2],
|
||||
time_dim=256,
|
||||
cond_dim=384,
|
||||
total_freq_bins=512,
|
||||
hr_freq_bins=hr_freq_bins,
|
||||
feature_enc_layers=4,
|
||||
cond_dropout_prob=0.1,
|
||||
sr_to_lr_bins=sr_config, # Pass the dictionary
|
||||
)
|
||||
|
||||
x = torch.randn(batch_size, 2, hr_freq_bins, T)
|
||||
y = torch.randn(batch_size, 2, lr_freq_bins, T)
|
||||
t = torch.randint(0, 1000, (batch_size,))
|
||||
sr_values = [12] * batch_size
|
||||
|
||||
print("\n--- Model Summary ---")
|
||||
summary(
|
||||
model,
|
||||
input_data=[x, t, y, sr_values],
|
||||
depth=4,
|
||||
col_names=("input_size", "output_size", "num_params",
|
||||
"kernel_size", "mult_adds", "trainable"),
|
||||
verbose=1
|
||||
)
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
+135
@@ -0,0 +1,135 @@
|
||||
import math
|
||||
from abc import ABC, abstractmethod
|
||||
from typing import Optional
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from einops import rearrange
|
||||
from torch import Tensor
|
||||
|
||||
class InvertibleFeatureExtractor(nn.Module, ABC):
|
||||
"""
|
||||
An invertible feature extractor, i.e. a one-to-one mapping that has a forward and a true inverse.
|
||||
It should hold up to numerical error that `extractor.invert(extractor(x)) == x`.
|
||||
"""
|
||||
@abstractmethod
|
||||
def forward(self, x, **kwargs):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def invert(self, x, **kwargs):
|
||||
pass
|
||||
|
||||
def analysis_synthesis(self, x, **kwargs):
|
||||
return self.invert(self.forward(x, **kwargs), **kwargs)
|
||||
|
||||
class AmplitudeCompressedComplexSTFT(InvertibleFeatureExtractor):
|
||||
"""
|
||||
A convenient composition of ComplexSTFT() and CompressAmplitudesAndScale().
|
||||
"""
|
||||
def __init__(
|
||||
self,
|
||||
window_fn, n_fft, sampling_rate,
|
||||
alpha, beta, comp_eps,
|
||||
hop_length=None, n_hops=None,
|
||||
learnable_window=False,
|
||||
*args, **kwargs,
|
||||
):
|
||||
super().__init__(*args, **kwargs)
|
||||
self.complex_stft = ComplexSTFT(
|
||||
window_fn, n_fft, sampling_rate, hop_length=hop_length, n_hops=n_hops,
|
||||
learnable_window=learnable_window,
|
||||
)
|
||||
self.compress = CompressAmplitudesAndScale(
|
||||
compression_exponent=alpha,
|
||||
scale_factor=beta,
|
||||
comp_eps=comp_eps,
|
||||
)
|
||||
|
||||
def forward(self, x: Tensor, **kwargs):
|
||||
X = self.complex_stft(x, **kwargs)
|
||||
out = self.compress(X, **kwargs)
|
||||
return out
|
||||
|
||||
def invert(self, X: Tensor, **kwargs):
|
||||
X = self.compress.invert(X, **kwargs)
|
||||
x = self.complex_stft.invert(X, **kwargs)
|
||||
return x
|
||||
|
||||
|
||||
class ComplexSTFT(InvertibleFeatureExtractor):
|
||||
def __init__(
|
||||
self, window_fn, n_fft, sampling_rate, hop_length=None, n_hops=None, learnable_window=False,
|
||||
*args, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
assert (hop_length is not None) ^ (n_hops is not None),\
|
||||
"Exactly one of {hop_length, n_hops} must be specified!"
|
||||
if hop_length is None:
|
||||
hop_length = int(math.ceil(n_fft / n_hops))
|
||||
|
||||
window_fn = getattr(torch.signal.windows, window_fn)
|
||||
self.learnable_window = learnable_window
|
||||
self.window = nn.Parameter(window_fn(n_fft), requires_grad=learnable_window)
|
||||
self.n_fft = n_fft
|
||||
self.hop_length = hop_length
|
||||
self.sampling_rate = sampling_rate
|
||||
self.center = True
|
||||
|
||||
def forward(self, x: Tensor, **kwargs):
|
||||
"""Assumes x is an audio tensor of shape [B, C, T] or [B, T]
|
||||
|
||||
[B,C,T] -> [B,C,F,T]
|
||||
[B,C,T] -> [B,F,T]
|
||||
|
||||
"""
|
||||
bc = "b c" if x.ndim == 3 else "b"
|
||||
X = torch.stft(
|
||||
rearrange(x, f"{bc} t -> ({bc}) t"), n_fft=self.n_fft, hop_length=self.hop_length,
|
||||
window=self.window.to(x.device), center=self.center,
|
||||
onesided=True, return_complex=True,
|
||||
)
|
||||
X = rearrange(X, f"({bc}) f t -> {bc} f t", b=x.shape[0])
|
||||
return X
|
||||
|
||||
def invert(self, X: Tensor, orig_length: Optional[int] = None, **kwargs):
|
||||
"""Assumes X is a (complex) spectrogram tensor of shape [B, C, F, T] or [B, F, T]"""
|
||||
bc = "b c" if X.ndim == 4 else "b"
|
||||
x = torch.istft(
|
||||
rearrange(X, f"{bc} f t -> ({bc}) f t"), n_fft=self.n_fft, hop_length=self.hop_length,
|
||||
window=self.window.to(X.device), center=self.center,
|
||||
onesided=True, return_complex=False,
|
||||
length=orig_length,
|
||||
)
|
||||
x = rearrange(x, f"({bc}) t -> {bc} t", b=X.shape[0])
|
||||
return x
|
||||
|
||||
class CompressAmplitudesAndScale(InvertibleFeatureExtractor):
|
||||
def __init__(self, compression_exponent: float, scale_factor: float, comp_eps: float, *args, **kwargs):
|
||||
super().__init__()
|
||||
self.compression_exponent = compression_exponent
|
||||
self.scale_factor = scale_factor
|
||||
self.comp_eps = comp_eps
|
||||
|
||||
def forward(self, X: Tensor, **kwargs):
|
||||
"""
|
||||
Assumes X is a complex STFT (complex spectrogram).
|
||||
"""
|
||||
alpha = self.compression_exponent
|
||||
beta = self.scale_factor
|
||||
if alpha != 1:
|
||||
X = X + self.comp_eps
|
||||
X = X.abs()**alpha * torch.exp(1j * X.angle())
|
||||
return X * beta
|
||||
|
||||
def invert(self, X: Tensor, **kwargs):
|
||||
"""
|
||||
Assumes X is an amplitude-compressed and scaled complex STFT.
|
||||
"""
|
||||
alpha = self.compression_exponent
|
||||
beta = self.scale_factor
|
||||
X = X / beta
|
||||
if alpha != 1:
|
||||
X = X.abs()**(1/alpha) * torch.exp(1j * X.angle())
|
||||
return X
|
||||
|
||||
|
||||
Reference in New Issue
Block a user