ComfyUI nodes for UniverSR (ICASSP 2026) — vocoder-free audio super-resolution (8/12/16/24 kHz → 48 kHz) via flow matching. - UniverSR Model Loader: presets auto-download to models/universr, plus local dir / raw .pth (from_local) loading, with caching. - UniverSR Super-Resolution: chunked overlap-add for long audio, per-channel stereo, seed control with global-RNG isolation, wet/dry blend, and an optional before/after spectrogram. - Vendors the universr inference package under vendor/ (prefers an installed copy); only extra dep beyond ComfyUI's stack is torchdiffeq. Co-Authored-By: Claude Opus 4.8 <noreply@anthropic.com>
ComfyUI-UniverSR
ComfyUI nodes for UniverSR — Unified and Versatile Audio Super-Resolution via Vocoder-Free Flow Matching (ICASSP 2026, arXiv:2510.00771).
A single model upscales 8 / 12 / 16 / 24 kHz effective bandwidth → 48 kHz across speech, music and sound effects. It works directly in the complex‑STFT domain with flow matching — no neural vocoder — and regenerates the missing high‑frequency band rather than just interpolating.
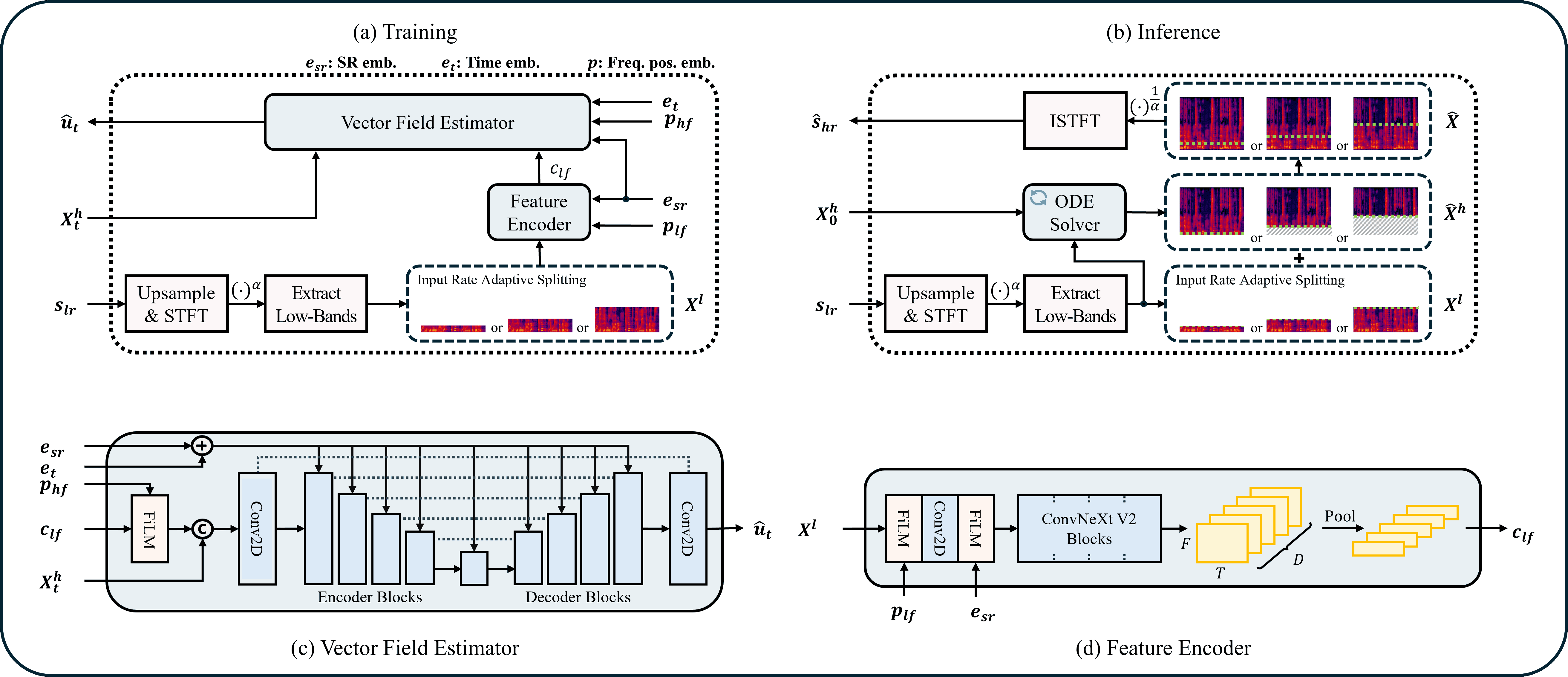
Nodes
| Node | Output | Purpose |
|---|---|---|
| UniverSR Model Loader | UNIVERSR_MODEL |
Loads + caches a checkpoint. Auto-downloads the presets to models/universr/. |
| UniverSR Super-Resolution | AUDIO, IMAGE |
Runs the SR. Chunks long audio (click-free overlap-add). Optional before/after spectrogram. |
Wire it up:
LoadAudio ─────────────┐
▼
UniverSR Model Loader ─► UniverSR Super-Resolution ─► SaveAudio
└─ spectrogram ─► PreviewImage
Model Loader
- model —
universr-audio(general; music/SFX/mixed, recommended) oruniversr-speech(voice). Each downloads ~230 MB tomodels/universr/<name>on first use. Local checkpoint folders placed inmodels/universr/also appear in this list. - device —
auto/cuda/cpu. - local_path (optional) — override with a folder (
config.yaml+pytorch_model.bin) or a raw.pth/.ckpttraining checkpoint. - config_path (optional) —
config.yamlfor a raw checkpoint. Empty → the bundled default config.
Super-Resolution
- input_sr — the effective bandwidth of your content in Hz. The model treats everything up to
input_sr/2as valid and regenerates above it.8000→ genuine low-rate audio (8 kHz → 48 kHz; the strongest, best-trained case).16000→ brighten muffled but full-rate audio by regenerating only above 8 kHz (most natural).
- ode_method —
euler(fastest) →midpoint(balanced) →rk4(best). - ode_steps — flow-matching steps.
4is fast and validated;4–10is a good range. - guidance_scale — classifier-free guidance. Speech
1.0–1.5, music1.5–2.0, SFX~1.5. Higher = denser highs but less faithful.0disables CFG. - seed — noise seed (
0= random each run). - chunk_seconds / overlap_seconds — long-audio handling (see below).
chunk_seconds=0processes the whole clip at once. - blend — wet/dry mix.
1.0= full SR. Lower keeps more of the original (handy for bandwidth extension of already-48 kHz audio). - unload_model — free VRAM after the run.
- show_spectrogram — also output a before/after spectrogram comparison
IMAGE.
Long audio & chunking
UniverSR runs the whole clip through a flow-matching ODE in one shot, which OOMs on long files
(the upstream notebook added chunking specifically to survive clips > 2 min). This node chunks in the
time domain and stitches the results with overlap-add + linear crossfade (weight-normalised), so
seams are click-free — an improvement over the upstream GUI's naive concatenation. Drop
chunk_seconds if you hit VRAM limits; raise overlap_seconds if you ever hear a seam. Stereo is
processed per-channel and preserved.
Compared to the
FoleyTune BWEnode (which brightens short foley clips and processes the whole clip at once), this node adds the chunking needed for arbitrarily long sequences.
Installation
cd ComfyUI/custom_nodes
git clone <this repo> ComfyUI-UniverSR
pip install -r ComfyUI-UniverSR/requirements.txt
The universr model code is vendored under vendor/ (an installed pip copy is preferred if
present), so the only dependency beyond ComfyUI's stack is torchdiffeq (plus einops, timm,
huggingface_hub, pyyaml, which ComfyUI usually already has). Weights download automatically on
first use.
How it works (implementation note)
ComfyUI audio arrives at an arbitrary real sample rate. UniverSR's file path relies on
torchaudio.load (fragile torchcodec backend), and its tensor path assumes the tensor is already at
input_sr. So this node does the band-limit itself: resample to 48 kHz → downsample each chunk to
input_sr (pure DSP, no codec) → hand UniverSR a genuine low-rate tensor to super-resolve. This
exactly reproduces the model's training-time degradation.
Credits & license
UniverSR © Woongjib Choi et al., DSPAI Lab, Yonsei University — released under the MIT License
(see LICENSE). This node wrapper vendors the UniverSR inference code unmodified under vendor/.
@inproceedings{choi2026universr,
title = {{UniverSR}: Unified and Versatile Audio Super-Resolution via Vocoder-Free Flow Matching},
author = {Choi, Woongjib and Lee, Sangmin and Lim, Hyungseob and Kang, Hong-Goo},
booktitle = {IEEE ICASSP},
year = {2026}
}